Command Query Responsibility Segregation, or CQRS, is a well known architectural pattern which is often conflated with other design patterns resulting in an overcomplicated mess.
Segregation of commands and queries
CQRS only mandates different code paths for reading vs writing.
Hence it's name, segregation of the responsibility to handle commands (writing) and queries (reading).
The design patterns chosen to implement these paths should be different.
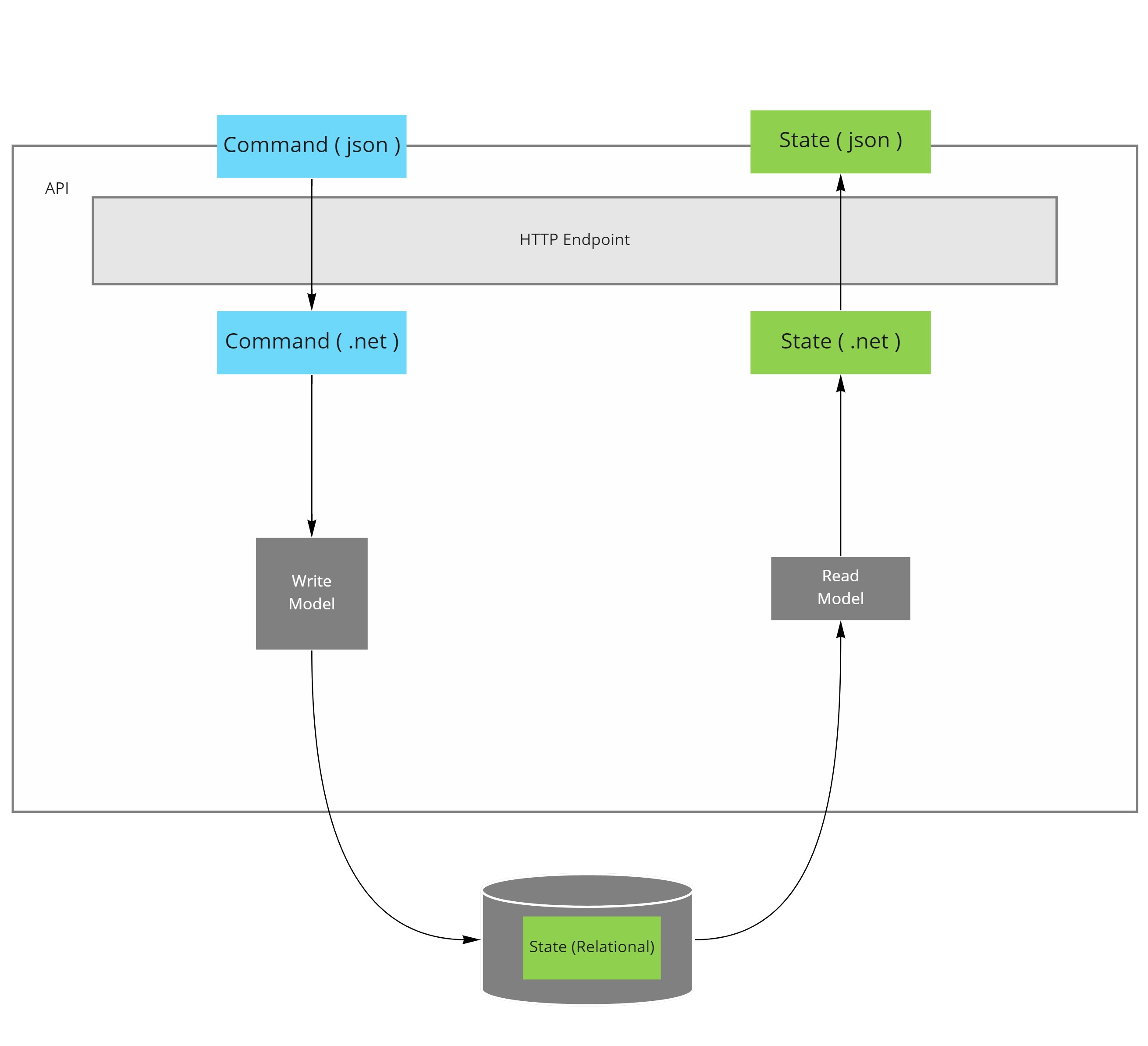
That's it though!
And nothing else
CQRS does not:
- Mandate what the write or read model should look like
- Require having separate databases for read and write
- Need separate processes hosting the read and write logic
- Tell you to use messaging to communicate between these processes
All of the above are consequences of the design patterns chosen to implement CQRS.
It's up to you to make conscious choices on which ones you want to layer in.
But I do advise to keep it as simple as required by the capability you are implementing.
My preferences
Personally I do have a preference for which patterns should be used.
These patterns are:
- Aggregate Root and Repository on the write side
- Projection and Registry on the read side
Both of these backed by Event Sourcing
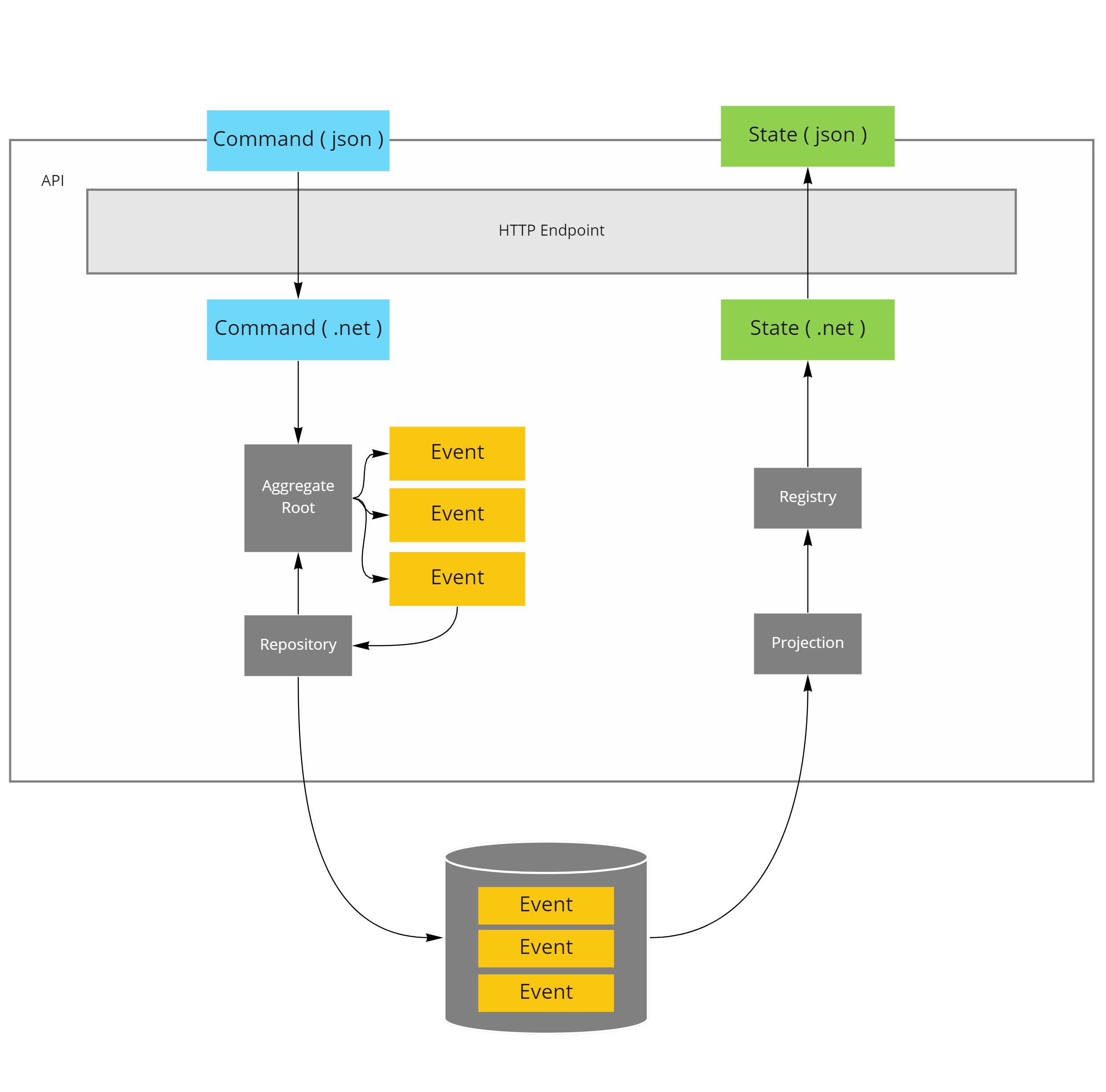
I have talked about Aggregate Root and Projection before when describing my full set of processing patterns, so I won't repeat these here.
Event Sourcing
I've read many times before that Event Sourcing would be more complex than a CRUD based approach using a relational data model, but that simply isn't true.
When using an event store the database schema is simple and consistent across all services in the system.
Once you have your stores schema, you can reuse it for all future services. That's one less thing to worry about.
Registry
Converting a stream of events, stored in the event store, in a state model is the job of a projection.
I like to associate my projections with a registry.
A registry is defined, in the book Patterns of Enterprise Application Architecture, as 'a well-known object that other objects can use to find common objects and services.'
Using a registry to index and query recently projected state objects is a great alternative instead of using a second database.
A registry can be implemented using simple memory sets such as dictionary to maintain the indexes of the projection results.
Repository
An aggregate root is responsible for encapsulating a section of the domain model and ensuring that invariants in that section aren't violated.
Because it has this repsonsibility anyway, it is the ideal pattern to take care of handling commands.
To mediate between the event store and the aggregate root, I'm using the repository pattern.
From a usage perspective repository and registry are lookalikes, the main difference is that a registry only maintains indexes of objects, where a repository handles the actual loading and persisting of objects from the underlying datastore.
When to use
I mainly use the CQRS pattern for implementing public API's, to be consumed by untrusted clients.
The CQRS pattern is ideal for this case as an Aggregate Root takes care of validating incoming commands and the projection can decide which information to expose.
For trusted clients, where I can safely store events in the browser, I also use this architectural pattern but client side. The api side will have to look very different in that case though.
What I don't do
More important than the patterns used, are the patterns not used.
By default I don't:
- Use multiple databases
- Use separate processes for the read and write sides
- Use a message bus to distribute commands nor events
Only when a situation requires distribution of data, process and communication I will add these patterns to the implementation, but more often than not, it's simply not required.


