In other posts I've already mentioned quite a few times that I prefer to use custom built static site generators for my jamstack sites and progressive web apps. The reasoning is that I think it is easier to compose a new generator from existing components, then it is to bend an existing, and often opinionated, one to my needs.
Today I'd like to share how I use the pipeline design pattern to quickly compose new generators from a set of existing components.
Pipeline Pattern
The pipeline pattern is a structural design pattern used for algorithms in which data flows through a sequence of tasks or stages in a well defined order.
This design pattern matches very well with the nature of a static site generator. It starts with content and metadata in a set of input files, which then need to be transformed, through a well known series of steps, into html files.
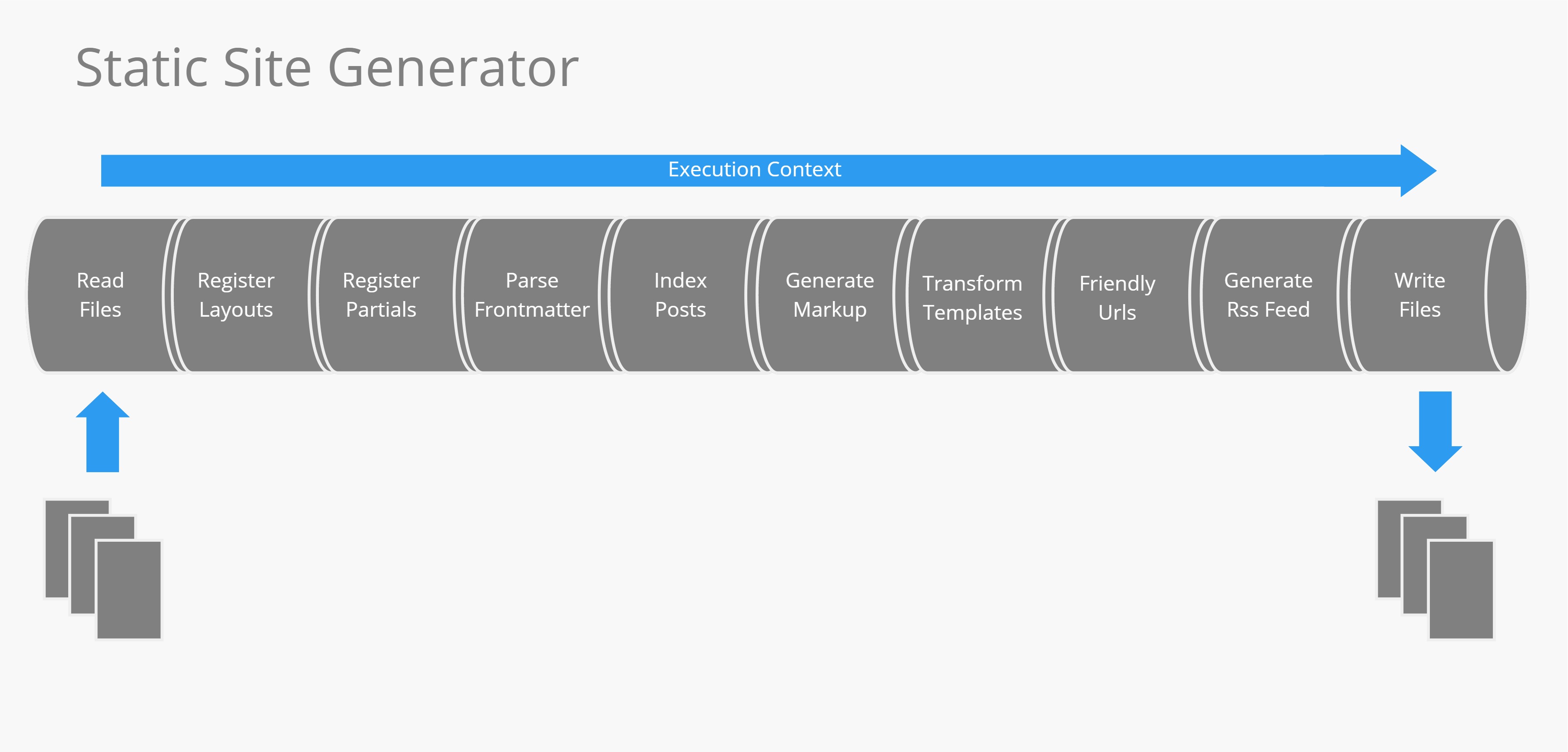
The series of steps required to generate a site, or web app, is different per site. As an illustration the image above shows the steps required to generate this blog. These steps will also serve as an example for the upcoming code samples (The code is in C#). But know that every site will have a different composition of its pipeline.
Pipeline Section
Each section in the pipeline is basically an implementation of the same interface, an interface which accepts a set of input documents and returns a set of output documents.
public interface IPipelineSection
{
Task<IEnumerable<IDocument>> Execute(
IEnumerable<IDocument> inputs,
IExecutionContext context);
}
The documents returned from one section will become the input documents for the next section. This way each section can choose to augment, filter or transform the set of documents in order to ultimately end up with a functioning site.
The execution context passed through all of the sections is intended to transport shared state between them. This is especially usefull for sections that created derived content which can subsequently be used in downstream steps. E.g. IndexPosts will create an index of all blogposts on the site, which can then be used from the templating engine in TransformTemplates to render a paging element at the bottom of the blog page.
Pipeline composition
My static site generation library, called Dish, contains a set of reusable sections, which can be composed together (usually with a few custom sections) into pipelines specifically suited for a target website or web app.
The following code snippet shows the content pipeline for this blog.
public static class ContentPipeline
{
public static PipelineExtensionPoint Content(this ConfigurationRoot configuration)
{
var settings = configuration.GetSettings();
var extensionPoint = configuration.ProcessingPipeline("content");
var basepath = settings.GetBasePath();
var contentFolder = Path.Combine(basepath, settings.GetContentFolder());
var outputFolder = Path.Combine(basepath, settings.GetOutputFolder());
var layoutsFolder = Path.Combine(basepath, settings.GetLayoutsFolder());
var partialsFolder = Path.Combine(basepath, settings.GetPartialsFolder());
extensionPoint.Pipeline.Sections.Add(new ReadFiles(contentFolder));
extensionPoint.Pipeline.Sections.Add(new RegisterLayouts(layoutsFolder));
extensionPoint.Pipeline.Sections.Add(new RegisterPartials(partialsFolder));
extensionPoint.Pipeline.Sections.Add(new ParseFrontMatter());
extensionPoint.Pipeline.Sections.Add(new IndexPosts());
extensionPoint.Pipeline.Sections.Add(new GenerateSocialMediaTags());
extensionPoint.Pipeline.Sections.Add(new GenerateMarkup());
extensionPoint.Pipeline.Sections.Add(new TransformTemplates());
extensionPoint.Pipeline.Sections.Add(new FriendlyUrls());
extensionPoint.Pipeline.Sections.Add(new GenerateRssFeed(outputFolder));
extensionPoint.Pipeline.Sections.Add(new WriteFiles(outputFolder));
return extensionPoint;
}
}
It uses the following sections:
- ReadFiles: Reads all the input files from a content folder.
- RegisterLayouts: Reads all the layout files (think of this as the structural parts of a page, such as header and footer placement) from a layouts folder and injects them into the templating engine.
- RegisterPartials: Reads all the partials files (think of this as reusable sections such as a menu or my bio) from a partials folder and injects them into the templating engine.
- ParseFrontMatter: Front matter is a term for page level metadata, in YAML format, that sits at the top of every content document. In this section that metadata gets parsed.
- IndexPosts: Creates an indexed structure of all the blog posts, so that a pager element can be generated from that index at the bottom of the blog page.
- GenerateSocialMediaTags: Generates content for the opengraph and twitter card protocols, based on the front matter or the body of a content document.
- GenerateMarkup: Generates HTML markup from markdown files.
- TransformTemplates: Uses a templating engine to generate pages from the content documents, layouts and partials.
- FriendlyUrls: Turns specific filenames, such as 'build-your-own-static-site-generator.html', into a folder and index file 'build-your-own-static-site-generator/index.html', making them easier to link.
- GenerateRssFeed: Generates the RSS Feed
- WriteFiles: Writes all the generated files to disk
Pipeline section configuration
The pipeline instance is wrapped into a configuration extension point instead of being exposed directly. This technique allows me to provide a fluent configuration API on top to configure certain implementation details and settings.
In this case, the FrontMatter parser uses the Yaml format, the templating engine uses Handlebars and the markup generator uses Markdown. Note that it generates links for every header (move your mouse in front of the header above to see the effect).
var configuration = new SiteGenerationConfiguration();
var content = configuration.Content()
.Yaml()
.Markdown(opts.HeadersAsLinks)
.Handlebars();
It is possible to define multiple pipelines this way, which will be chained together. E.g. progressive web apps often need follow up steps after content generation to compute file versions, modify the service worker for cache busting, set environment specific configuration files or perform javascript bundling etc... all these actions would typically go in a post processing pipeline.
Running the pipelines
Running the configured pipelines is mainly a matter of iterating all the pipeline instances, and for each pipeline iterate through the sections, passing in the outputs of each section as input to the next one, while maintaining the reference to the execution context stable. All of this logic is encapsulated in the Run method of the SiteGenerator class.
var generator = new SiteGenerator(configuration.GetSettings());
await generator.Run();
Dotnet core tool
Next to the Run command, there are a few other follow-up commands that are very convenient:
- generator.Serve: Runs a local Kestrel instance to serve the freshly generated content and sets up a file system watcher to regenerate the site content whenever a change occurs.
- generator.Publish: Publishes the generated content to an azure storage account backing a cdn endpoint.
These 3 functions, Run, Serve and Publish become extra convenient for local testing and debugging when you expose them as a command line app registered as a dotnet core tool. Which will allow you to run the commands similar to following statement.
c:\github\gl> dotnet goeleven serve --port 5004
The next step
If you plan to maintain a site or web app for an extended amount of time, I think it is well worth it to build a custom generator for it. There is a lot of content on the web that is being generated over and over by server side rendering, or by api's and client side scripting, but the content actually rarely changes. All this code would be better off implemented as a custom pipeline section.
I hope this design pattern can inspire you to build your own site generator and generate that content only when it actually changes.
Back to guide
This article is part of the building offline progressive web apps guide. Return to this guide to explore more aspects of building offline progressive web apps.


