'Data on the Inside vs Data on the Outside'
This guidance, originating from Pat Helland back in 2005, is of course also applicable when you decide to partition your system based on business capabilities.
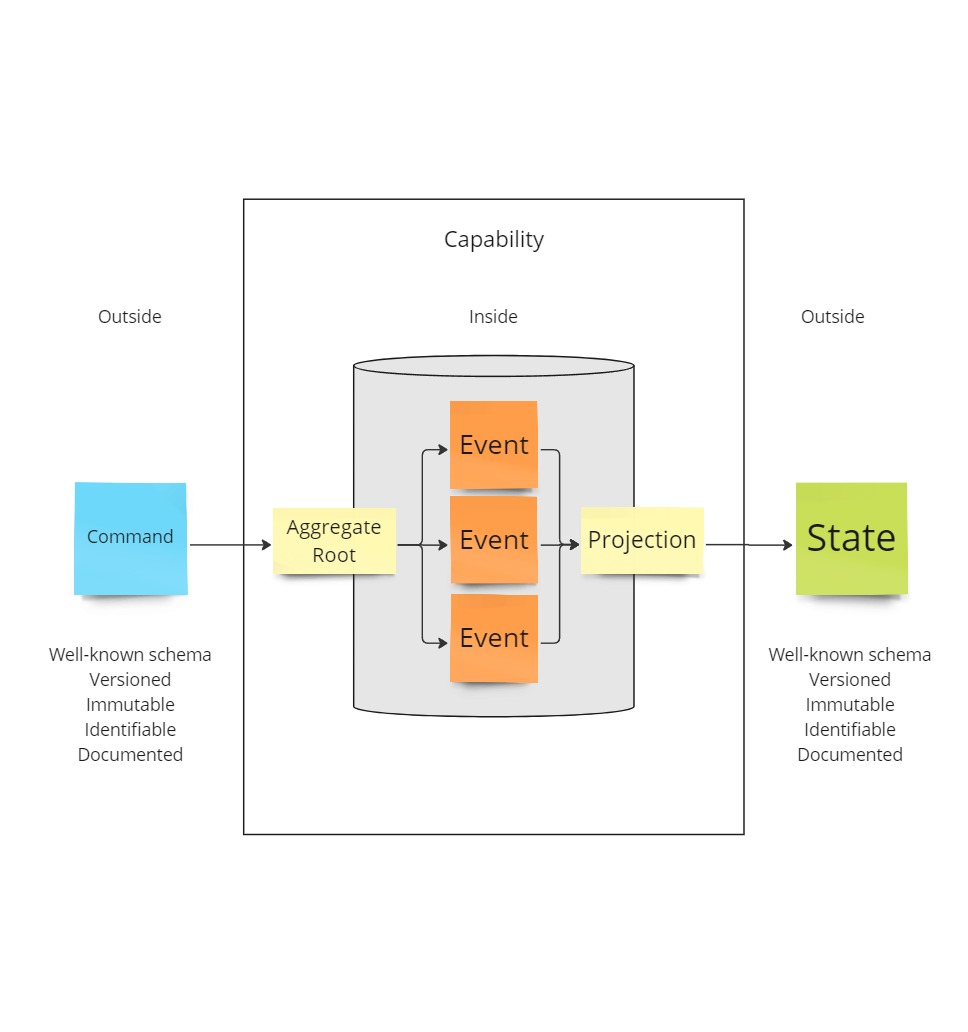
Data used internally in a capability should be treated differently from data exchanged between them.
Data on the outside
When capabilities are composed into a value stream, there may be up to three integration points where data is exchanged.
- Messages
- Shared data storage
- User Interface components
For each of these pieces of 'data on the outside', the teams maintaining either capability need to agree upon a few things.
A well known schema
The data format, referred to as a schema, should be well known by both teams and considered immutable.
Whenever a change is needed to the schema, a new version should be agreed upon and published.
The way of publishing should also be agreed upon, the main prerequisite is that it is agreed upon and versioning is possible: json-schema, shared assemblies in a nuget package or any other method... all fine.
Ideally both capabilities are both backward and forward compatible to the schema changes (for at least 1 version in either direction).
This to facilitate independent and gradual rollout of either side.
Immutable data
Each piece of data needs to be uniquely identified and have immutable contents that does not change as copies of it move around.
Copies can be passed from capability to capability, in which case the unique identifier must be passed along.
When new versions of the data are created, they should get a new unique identifier.
The identifier can be composed of a version independent identifier (such as an object ID) shared by all instances plus a version dependent identifier, e.g. a timestamp.
For reference data it may be ok to refer to it using only the version independent identifier, realizing that the data may be stale.
Avoid at all cost to base the version independent identifier on internal or technical details, such as database generated IDs.
Documentation
Immutability of data isn’t enough to ensure a shared understanding by both teams. The interpretation of the contents of the data must also be unambiguous.
Some data is inherently stable and unambiguous, e.g. entries on an accounting ledger, both others has a changing interpretation across space and time, e.g culturally sensitive expressions.
Therefore it is highly recommended to maintain written, and living, documentation about the interpretation of the content.
Furthermore, not all technologies have formal schema definitions.
There is for example no formal schema definition for html and css. There are some rules regarding naming variables, such as data-* attributes in html or --* variable names in css.
Frontend developers and UX designers solve this problem by maintaining a Design System, which is in essence living documentation about shared frontend components and styles.
Data on the inside
Data on the inside is invisible from the outside.
It can be represented in any form you like (I prefer event streams).
Incoming and outgoing data should be mapped to the internal structure.
Note that Pat called this shredding, but the community seems to call it mapping these days.


