When hosting the same aggregate in multiple locations their is a risk that conflicts appear between those instances.
This can occur in multiple scenarios:
- The same aggregate is hosted on both client and server
- It is hosted in multiple client instances
- It is hosted in multiple server instances
In this article I will show you how conflict can be resolved when using event sourcing as the persistence technique for the aggregate.
To make sure everyone reading this is on the same page, I will start of by repeating the very basics of what eventsourcing is.
If you are familiar with the concept already, skip ahead to the section on enforcing order.
The basics of event sourcing
Event sourcing is a persistence technique for storing aggregates.
Instead of storing an aggregate as a database record containing it's current state, you can also store it by creating an event for each decission it takes and then store a record per event.
The full set of events that make up the lifetime of an aggregate is called a stream.
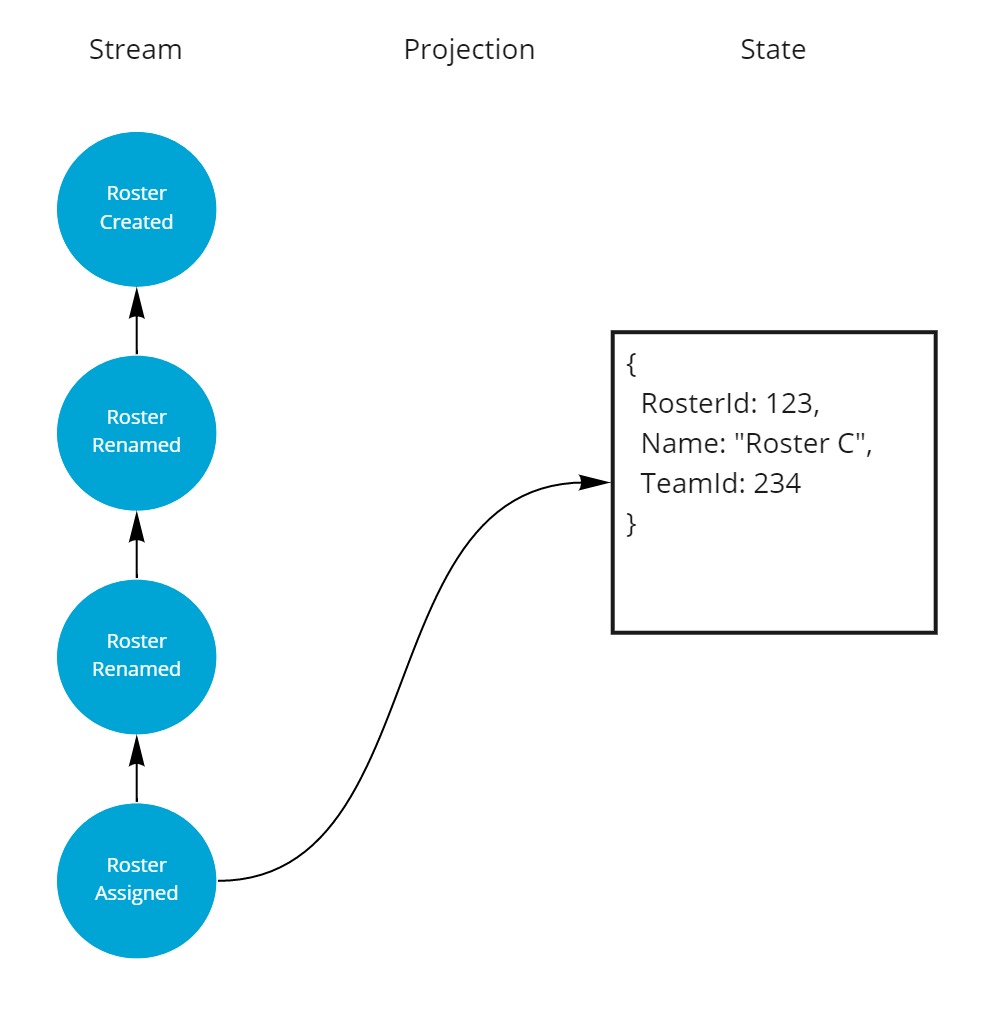
Here are the events that we'll use throughout the rest of the article.

From this stream of events, we can recreate the aggregate state at any point in time by copying the data event by event into member variables.
This concept is called a projection.
For example, right after a Roster was first created it would have the following state.
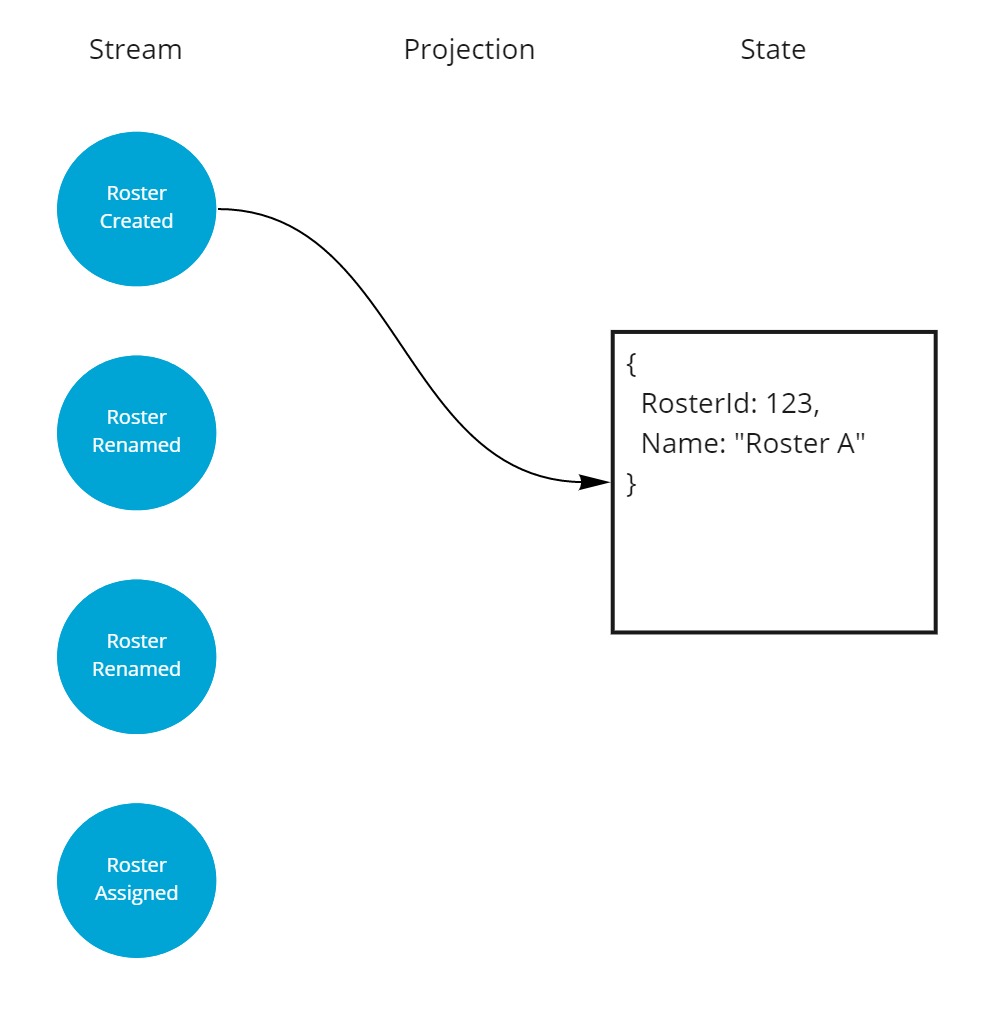
A second meaningful event in its lifetime was a rename, after the rename it looked like this.
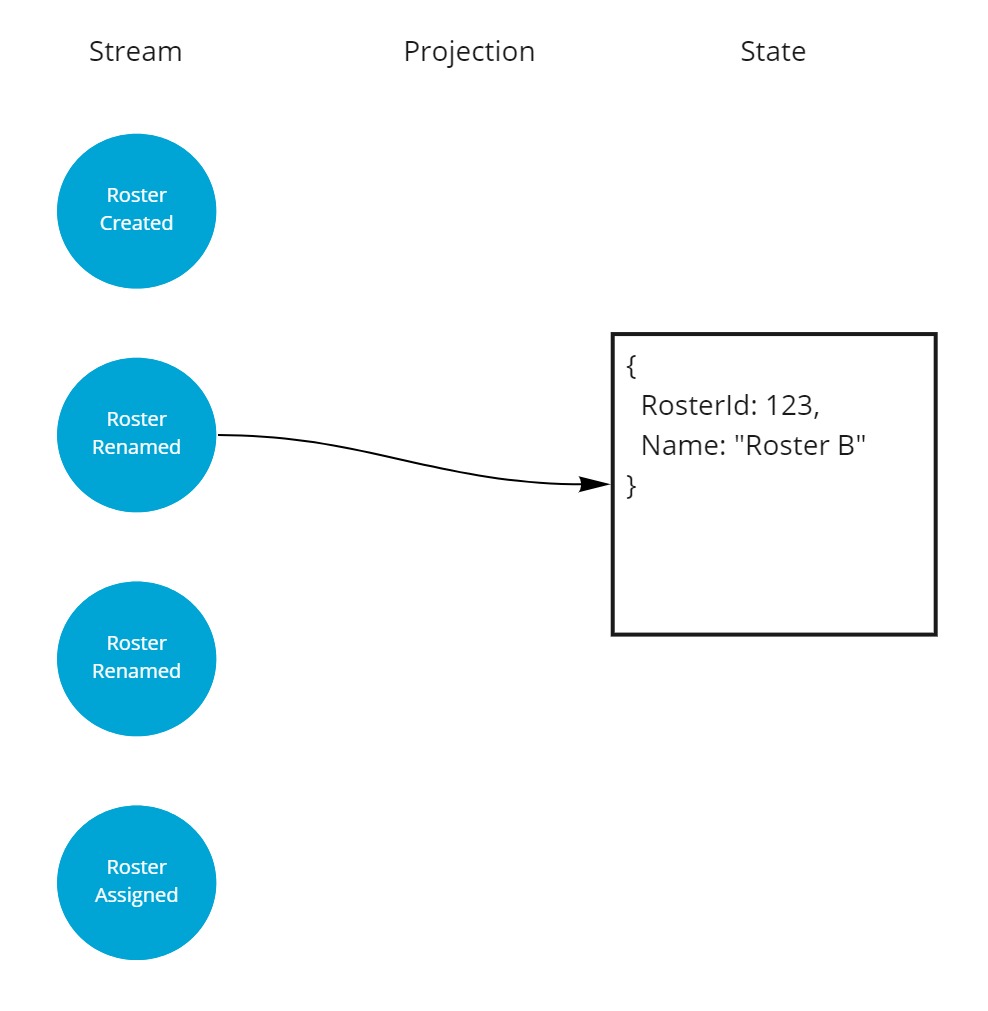
Then it got renamed again, and it was named "Roster C" from that point on.
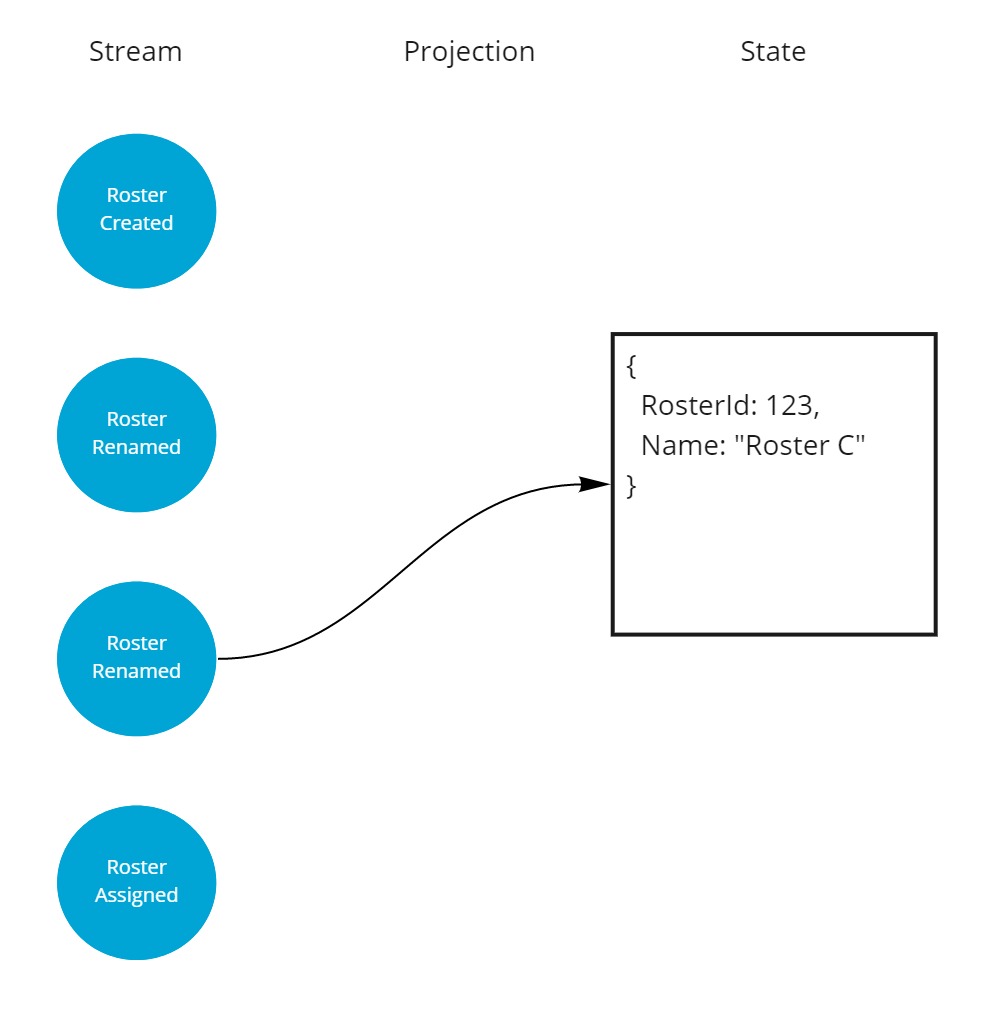
And finally the roster got assigned to a team and gained a new property.
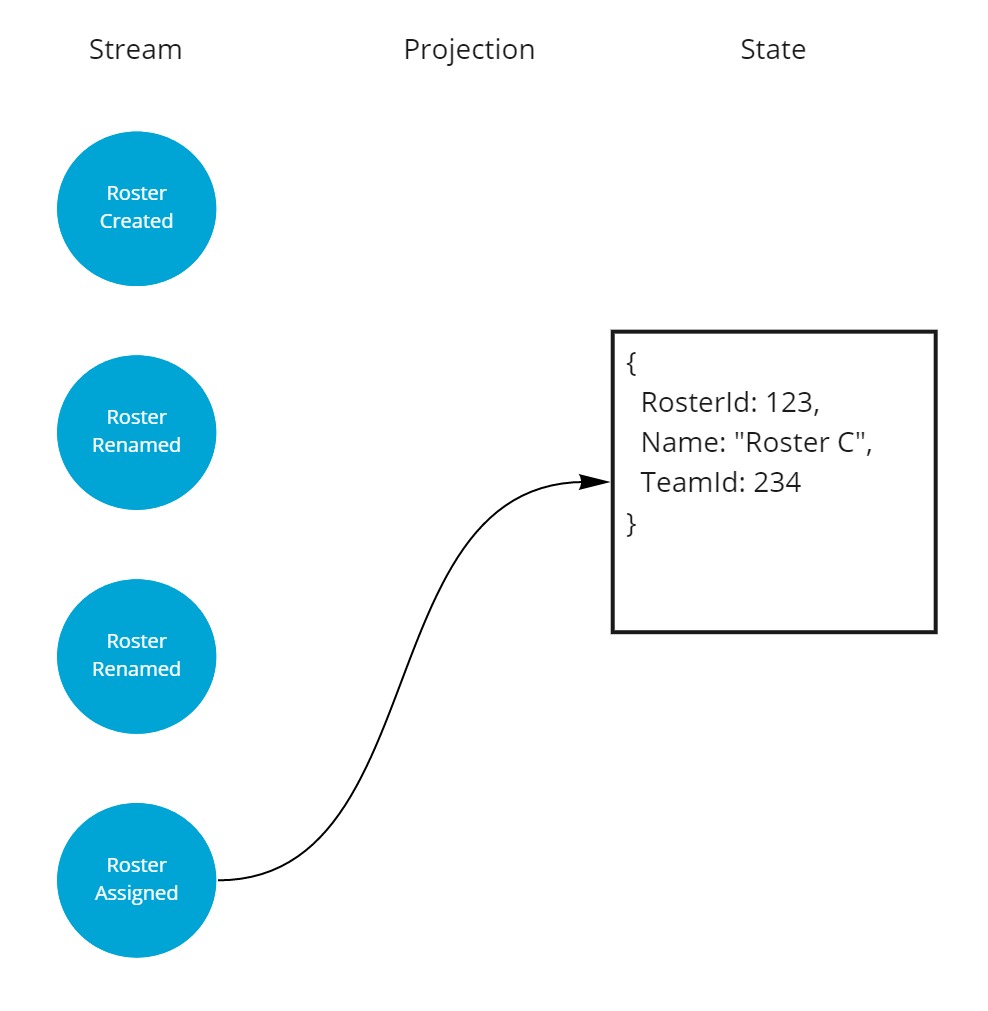
As you can guess, keeping the events in order of occurence is important to be able to deduce the correct state of the aggregate at any point in time.
On top of that, when there are multipe events of the same type, the last occurance will decide the value on the current state.
Enforcing order
There are different strategies to keep events in order.
Most frameworks I've seen so far add a version property to each event, this version property then contains a sequence number that can be used to sort the events in order.
I have however chosen a different strategy and turned the stream of events into a linked list.
A linked list is a linear collection of data elements whose order is not given by their physical placement in the list. Instead, each element points to the next. It is a data structure consisting of a collection of nodes which together represent a sequence.
In practice this means that each event has a ParentId property, which points to the event preceding it in the history.
Note: I also have a version property, but it is purely indicative and may contain duplicate values.
Using this strategy allows multiple events to have the same parent id, representing that they may be in conflict.
Synchronization with no conflict
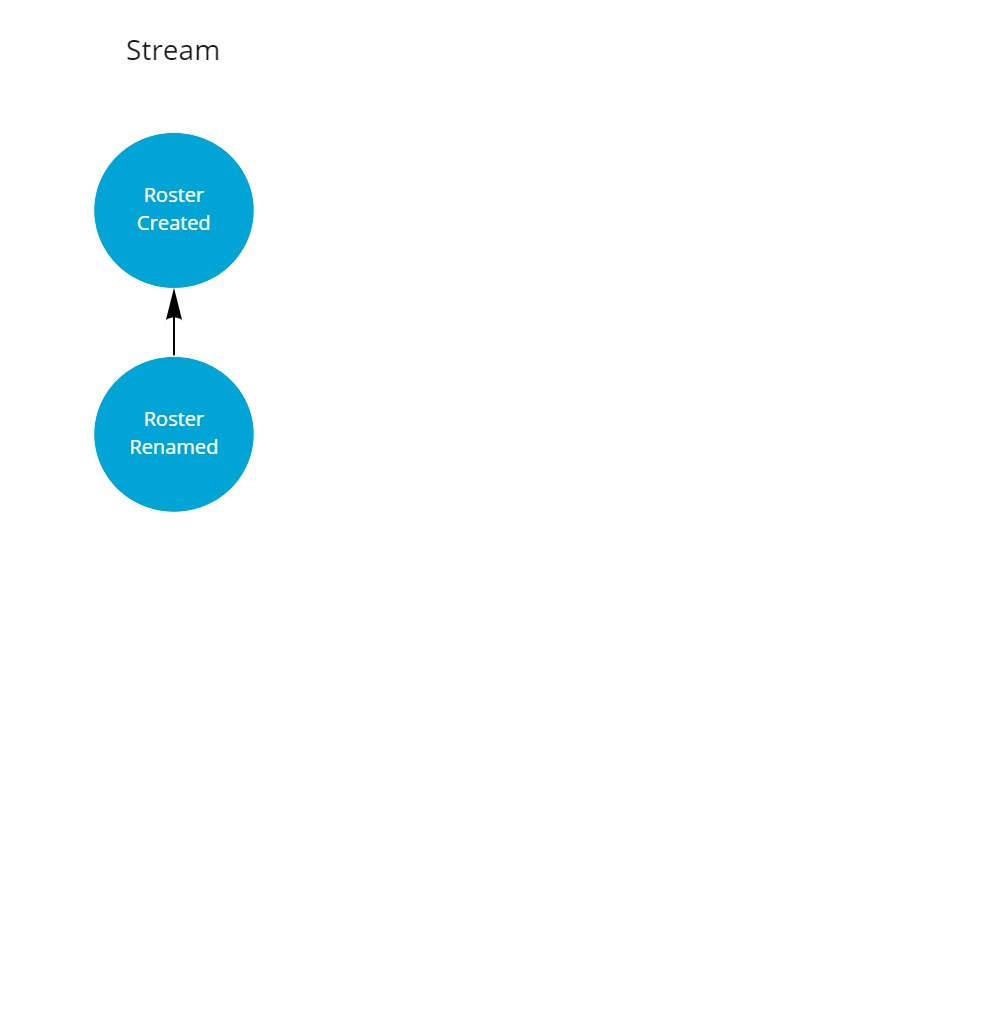
Let's have a look at how this model allows to synchronize multiple instances of the stream, initially without conflict.
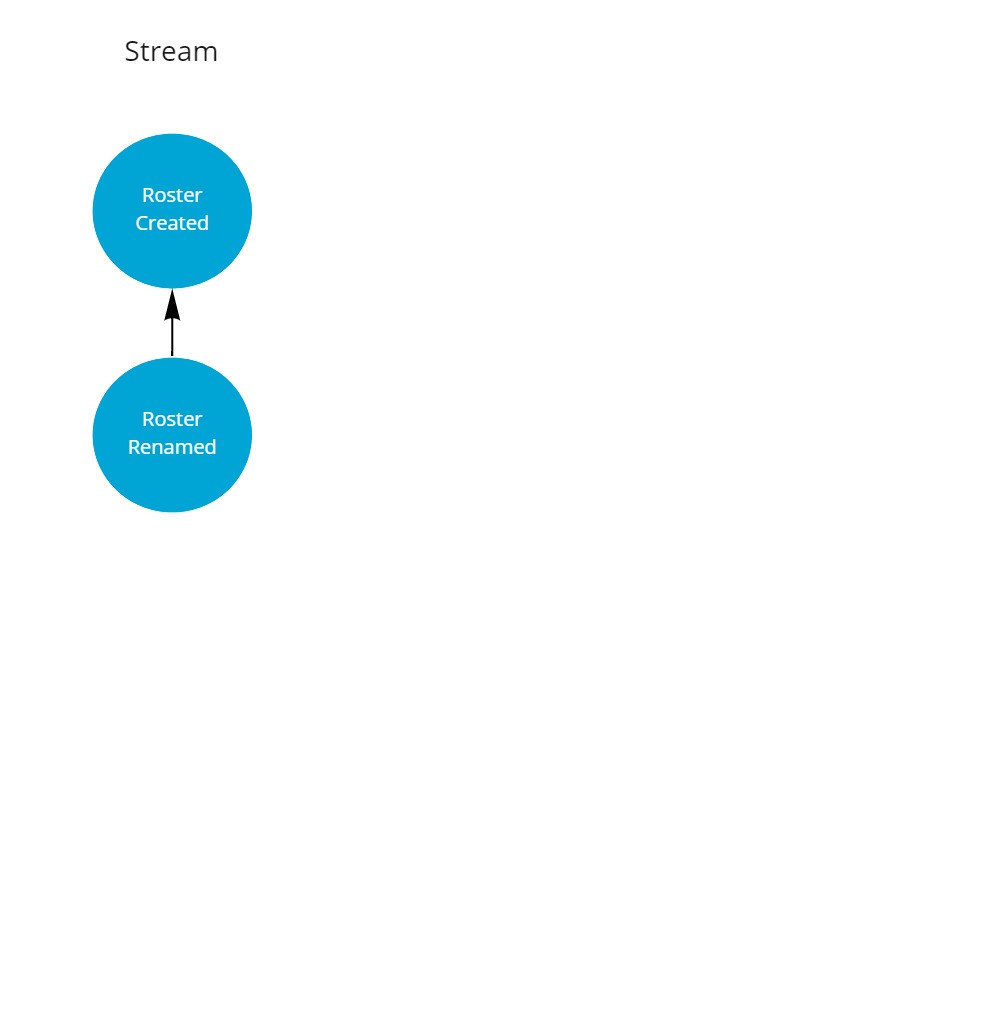
As a starting situation there is a stream with two events, e.g. on the server.
The roster has been created and renamed once.
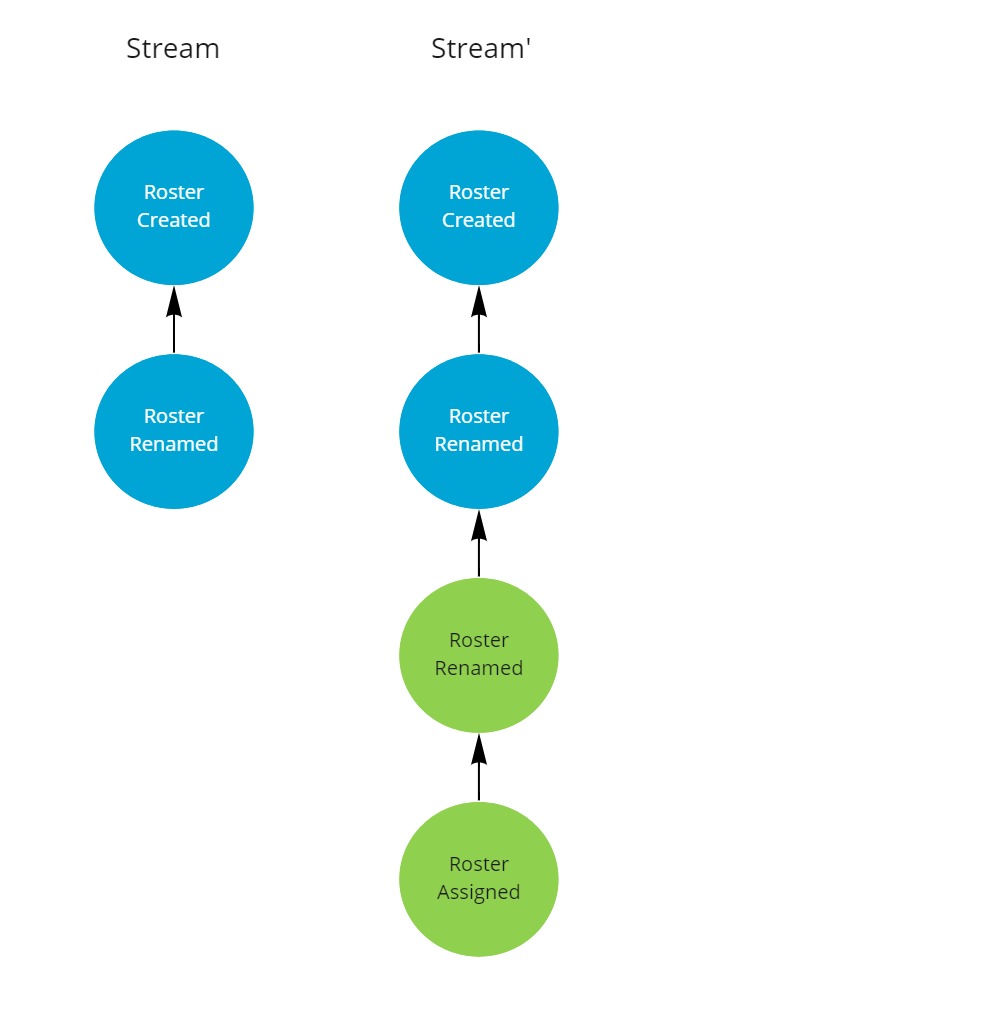
Now a replica gets created, e.g. on the client.
The local command handling logic appends two new events to the local stream. In this case another rename and an assignment.
On flush, the two new events are sent to the server and compared against the origin stream.
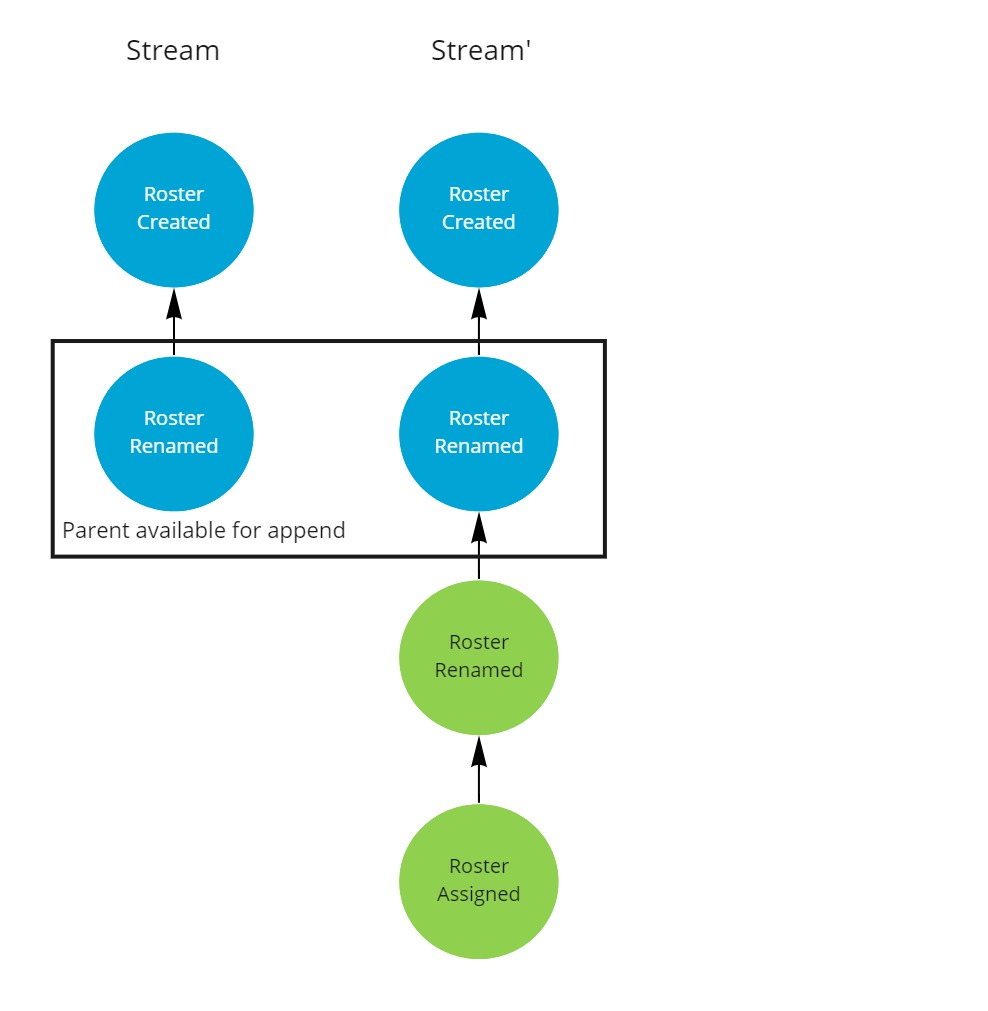
As the parent of the root of the changes is available, the two new events can be appended to the origin stream.
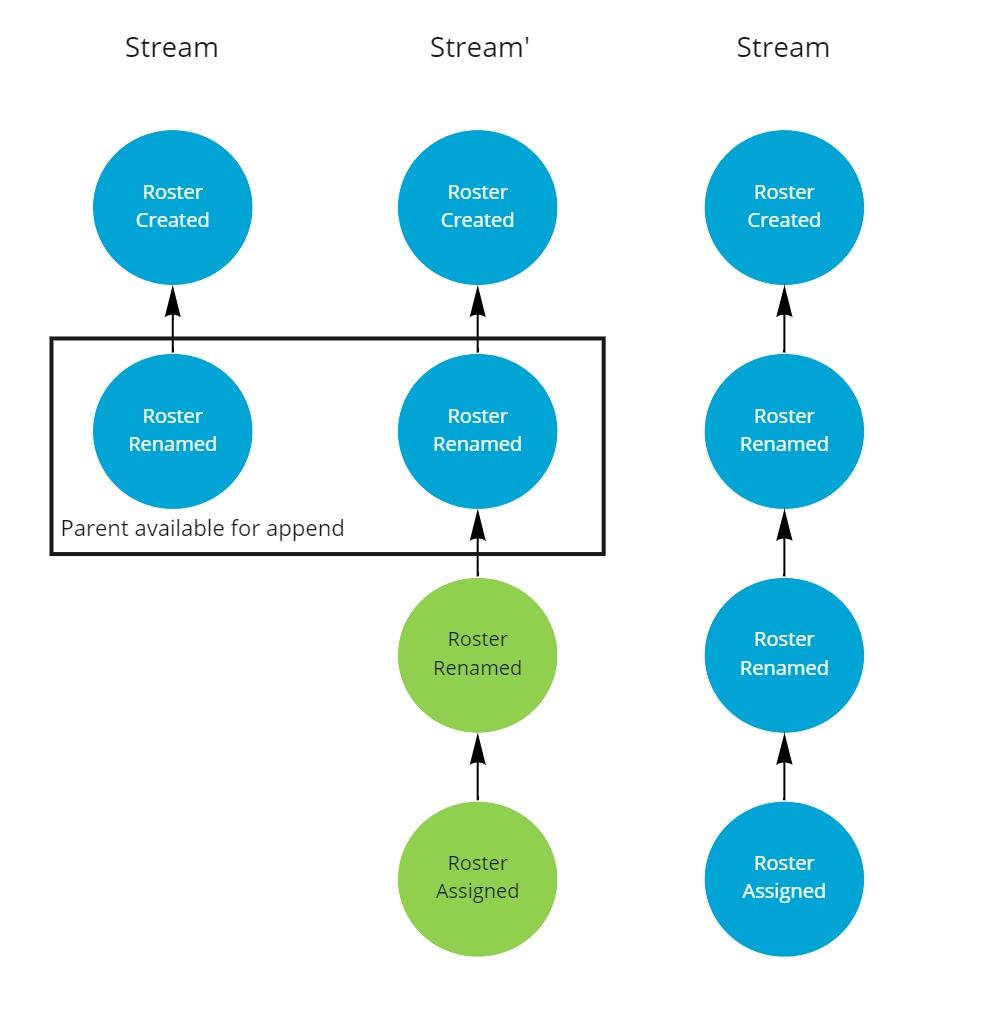
The two replicas are now back in sync.
Synchronization with conflict
Now lets have a look at a conflicting situation, starting off with the same begin situation.
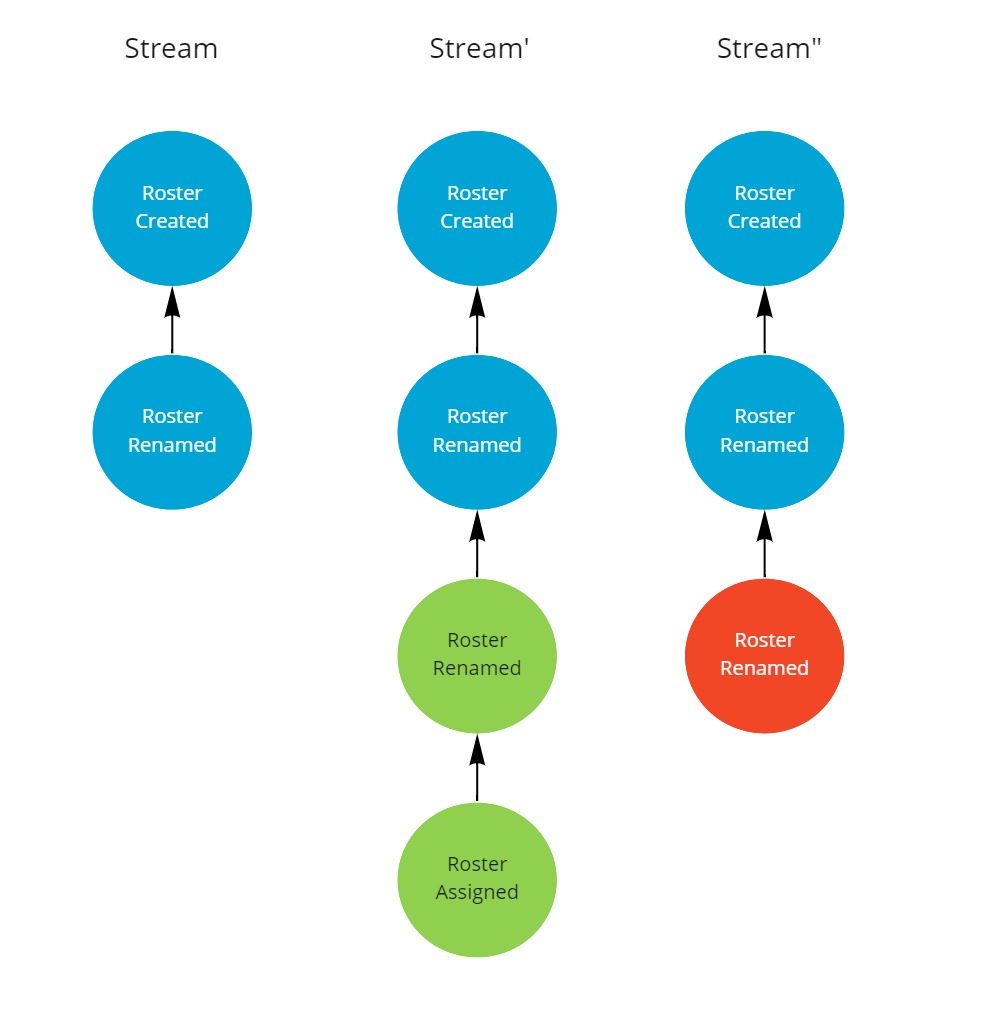
But instead of having only a single replica, we'll start of with two. This can happen when two clients work on the same aggregate at the same time.
Both clients perform a rename, with different values and thus cause a conflict.
The first client also assigns the roster to a team, this event does not cause a conflict.
Synchronizing the first replica will work fine, but when the second replica wants to synchronize it will be refused as the parent of the root of the synchronization set is no longer available.
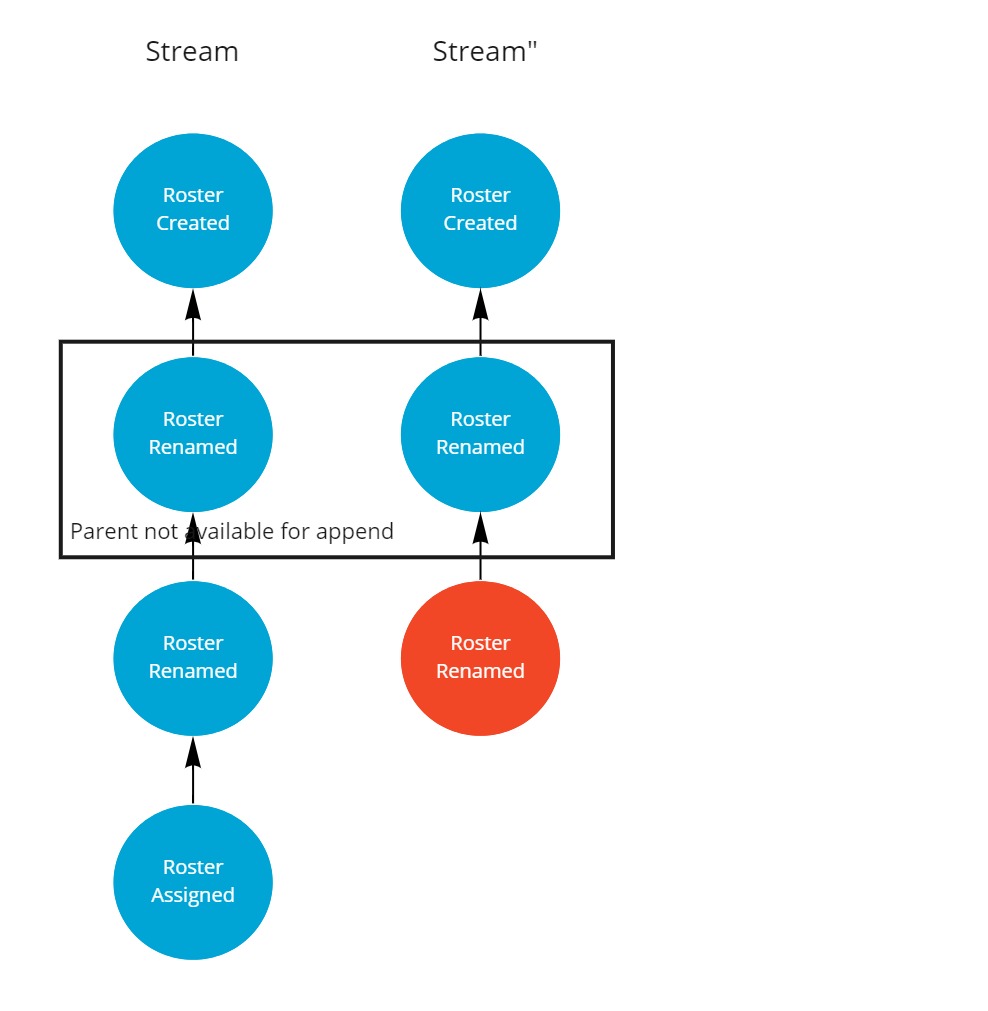
3 strategies to deal with conflict during synchronization
We can deal with the conflict situation in 3 different ways (names inspired by git).
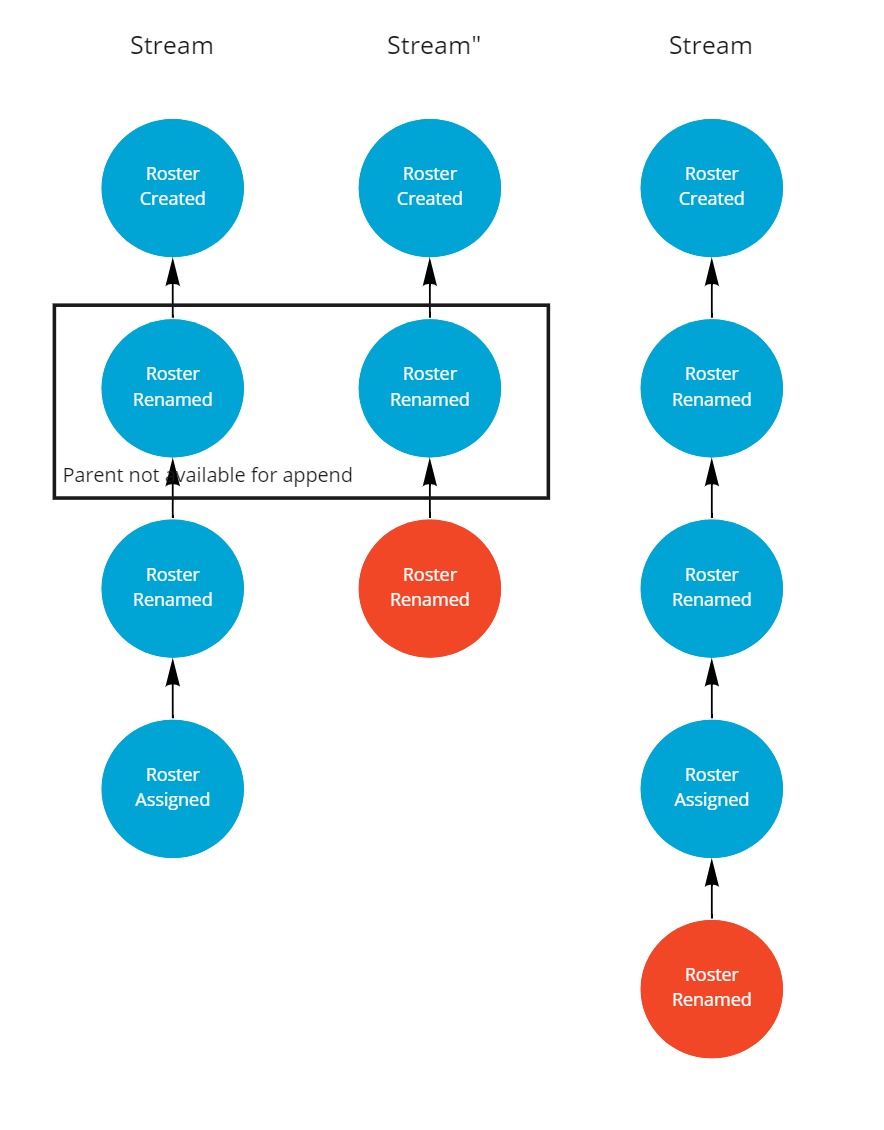
Rebase
In the first strategy, rebase, we'll change the parent of the root of the change set and point it to the last event in the origin stream.
By doing so, the conflicting event will be appended to the end of the stream and therefor overrule the previous rename.
Rebase upstream
The second strategy also works on the basis of changing the parent of part of the stream.
But this time we'll choose the parent of the upstream change set, which was appended in the first synchronization, and replace it by the last event in the second replica set.
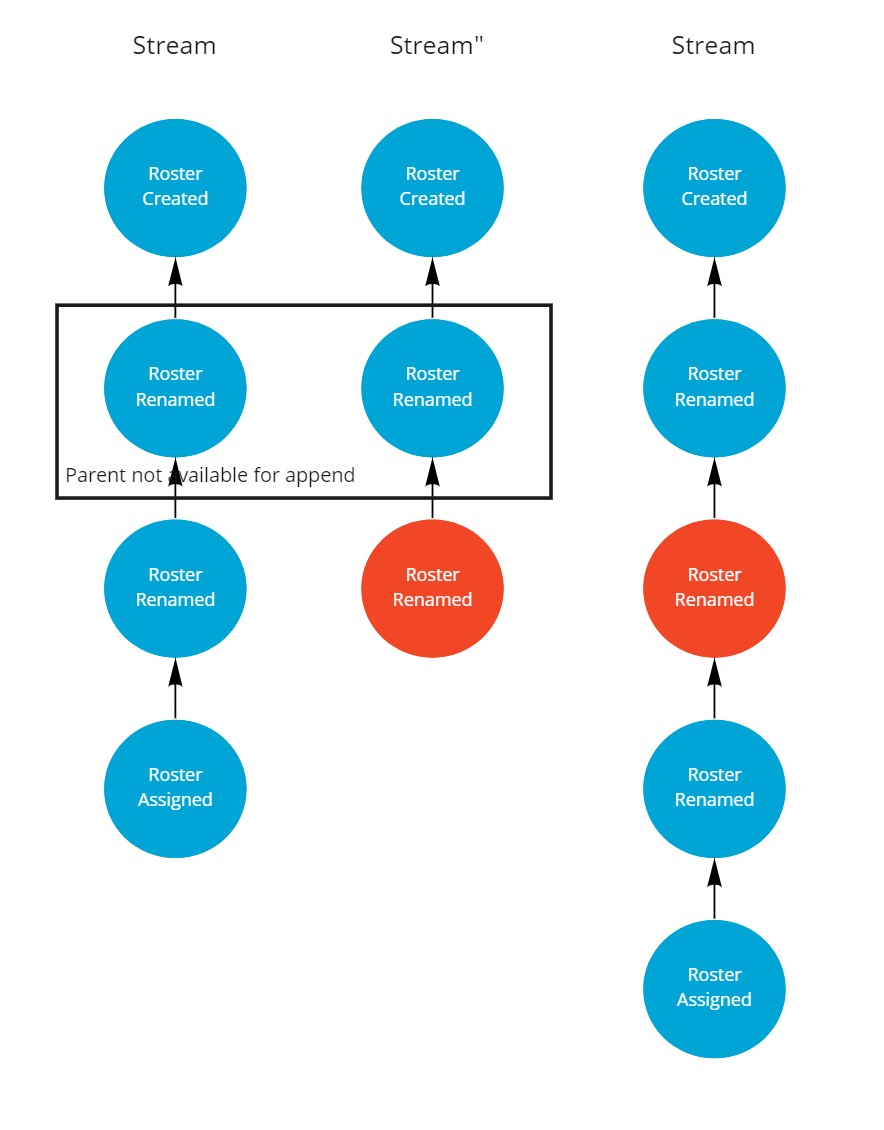
Using this strategy the conflicting rename event will not overrule the first.
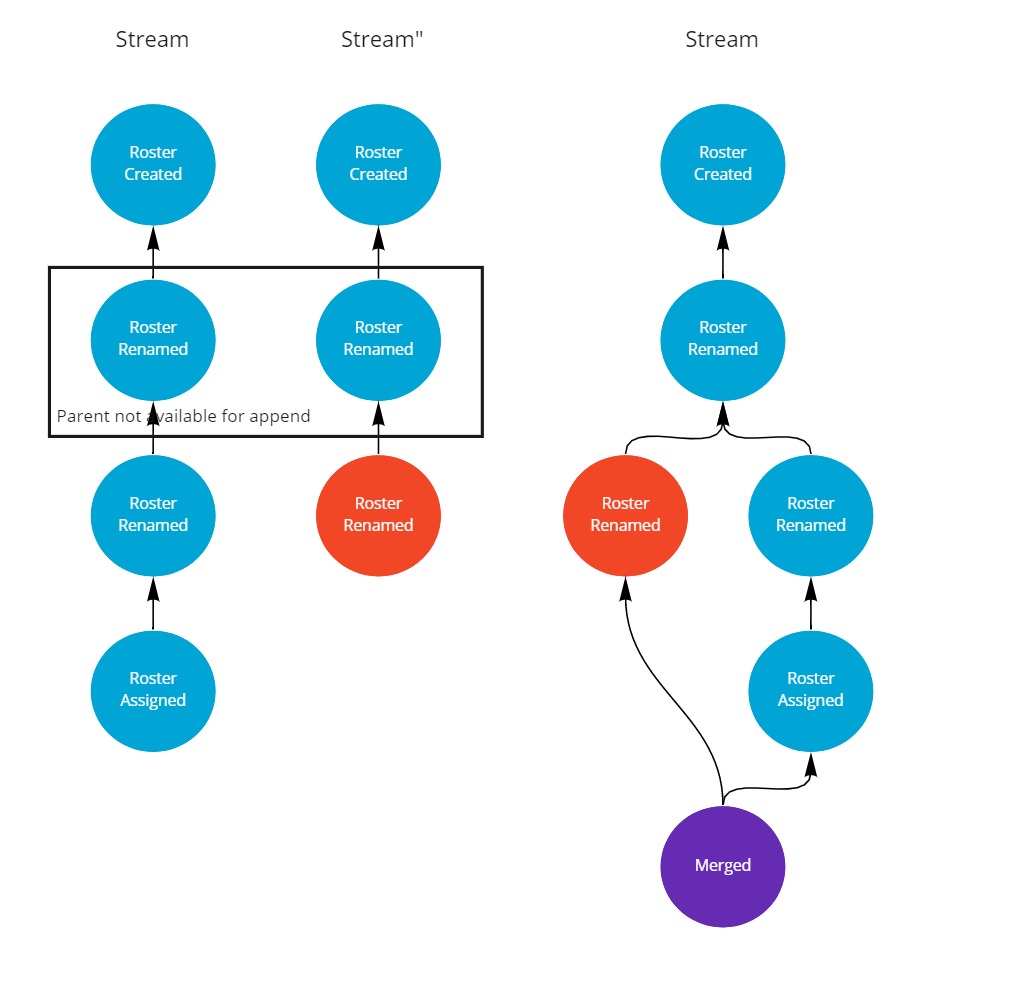
Merge
In the third strategy we'll allow both conflicts to co-exist.
This way two branches will appear in the stream.
To turn the branches back into a unified stream a Merged event is appended at the end.
This Merged event has two ParentId properties
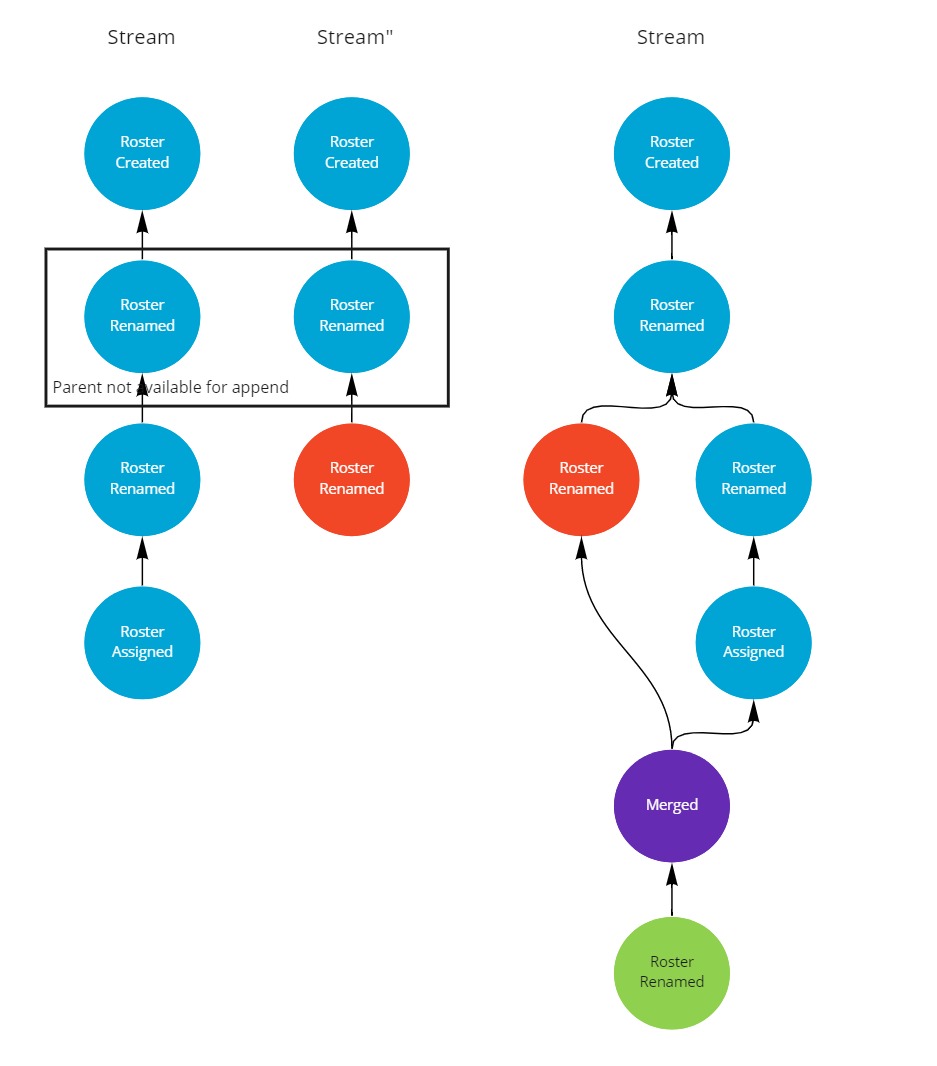
Using this strategy, the conflict is allowed to exist for a longer period of time.
Which in turn provides an opportunity to implement a corrective business process to resolve the conflict.
Wrapup
If you've been developing software for a while, you'll probably know how hard it is to keep replicas in sync and that there is no real good way to deal with conflicts between them.
Thanks to event sourcing you'll now have at least 3 different ways to deal with this problem.
Back to guide
This article is part of the building offline progressive web apps guide. Return to this guide to explore more aspects of building offline progressive web apps.


