Going offline
Due to legal liability laws, public wifi is rarely available here in Belgium.
Gyms are often large steel structures that act as a Faraday cage blocking all electromagnetic data signals.
Network connection is often hard to find.
Occasionally offline
Over the past few weeks I've introduced you to the CQRS architecture that I typically use for the clubmanagement API's and how you can use the cache aside pattern combined with the store and forward pattern to create an occasionally offline client on top of these API's.
Combined, this architecture looked like this:
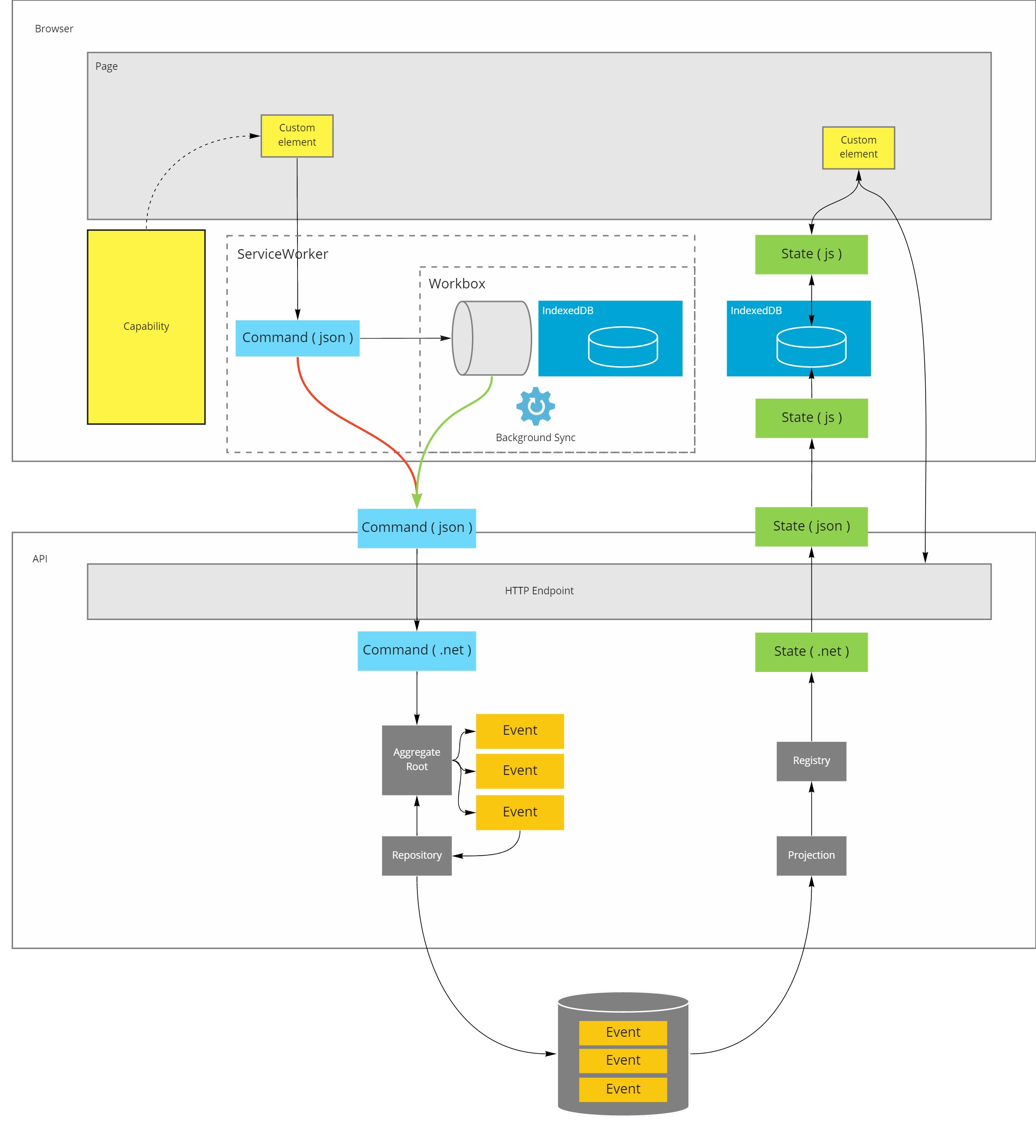
Staying offline
The inherent weakness of CQRS is the inconclusiveness of commands.
The longer it takes to learn about the outcome of a command, the higher the uncertainty, and thus an increased business risk of taking wrong decissions by the user.
To some extend you can deal with this increased risk, by modifying the user experience (e.g. telling them to wait for an email when the work is done), but such practices will come at a cost for their productivity.
To truly allow a user to work offline, for extended amounts of time, you have no choice but to move the server side logic into the client.
Client side event sourcing
By applying the exact same patterns in an offline client as you would otherwise have used at the server side, will make that the client can go offline forever.
- IndexedDB can serve as the local event store
- Commands are handled by an aggregate root
- A repository is responsible for the mediation between the event store and the aggregate root
- On the read side a projection generates the data to be displayed from the stream of events stored in indexedDB
- Optionally a registry can be used to extend the querability of a projection.
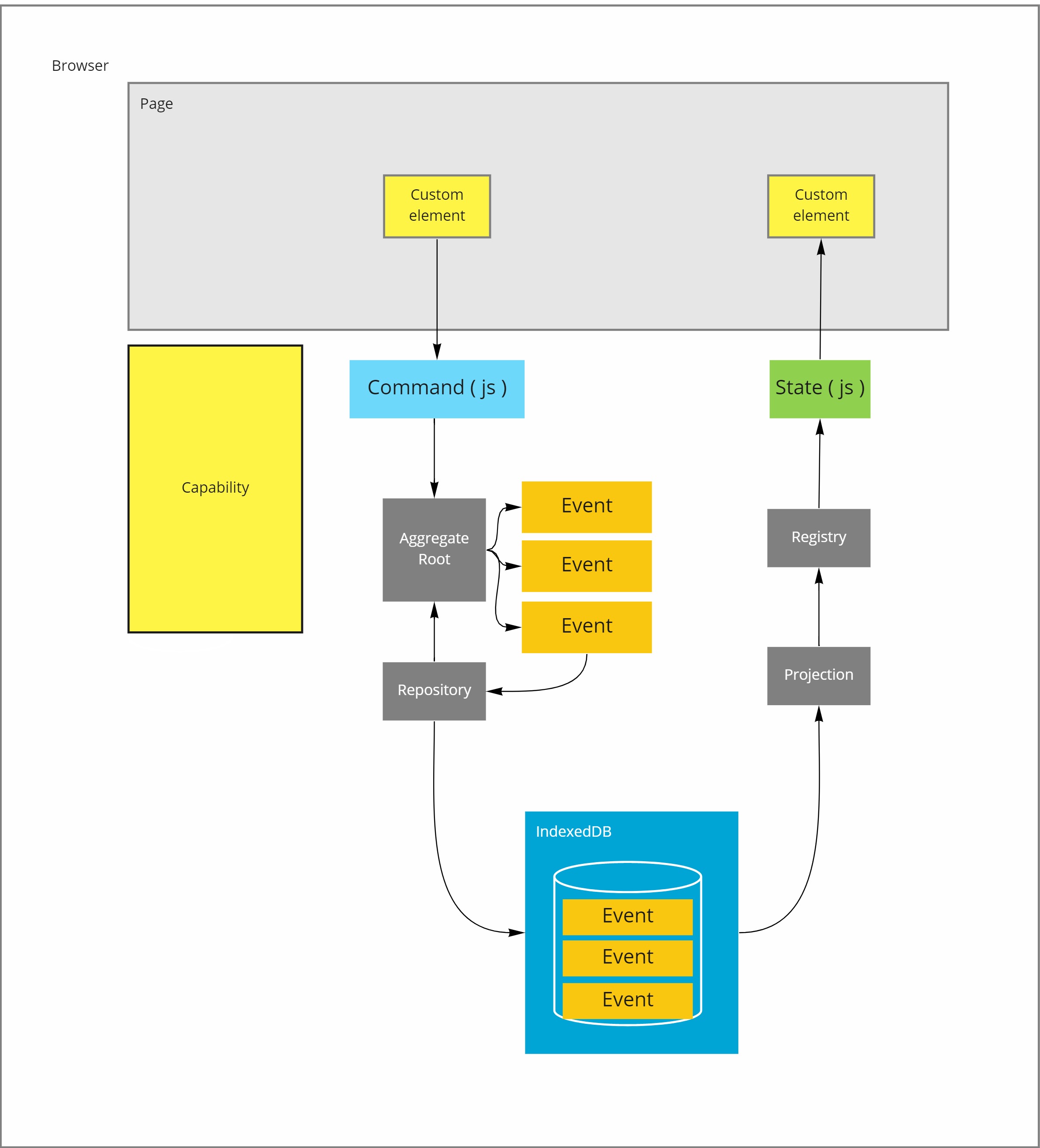
This design provides you a fully offline app, which can't go online, yet!
The online/offline spectrum
Fully offline applications will not be able to compete with the average Excel file though.
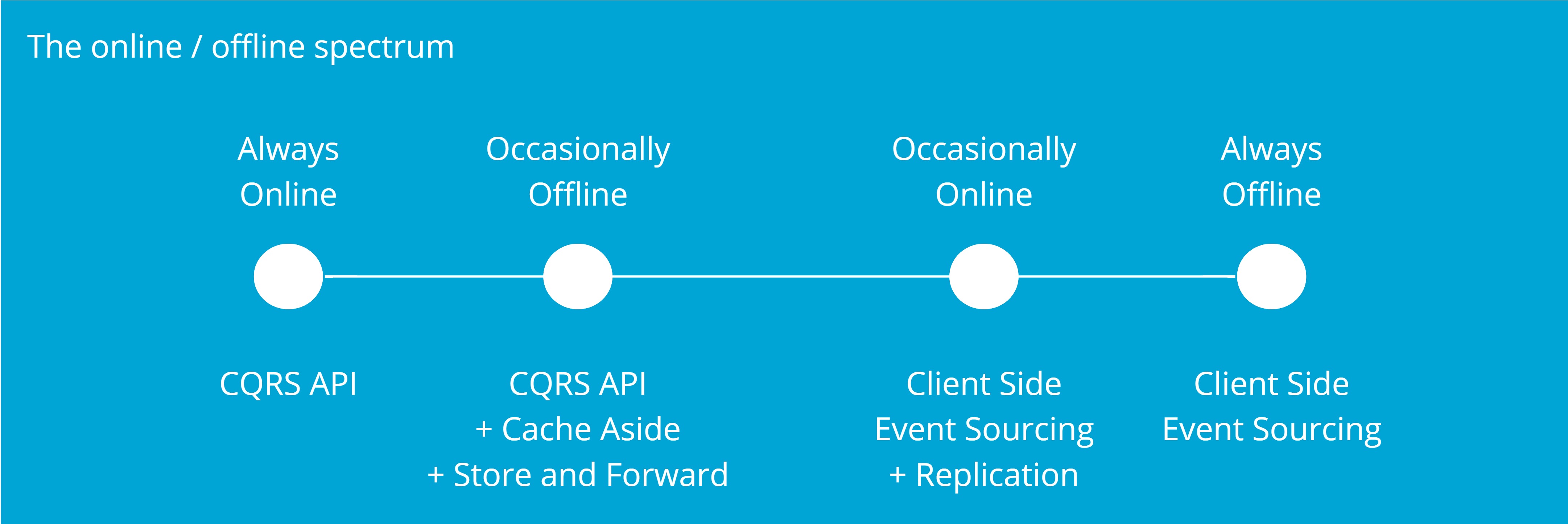
To be usefull, the changes made offline will need to be synchronized with the rest of the system whenever the application comes online again.
As events represent facts from the past that can never be undone, they are by definition immutable.
This makes synchronization easier as the act gets reduced to simple replication of new events. There can be no changes to past events, so those don't need to be synchronized.
To make replication possible, both the client and the API need to be prepared for it. So by definition this design can only be used for capabilities where the same team controls both the client as well as the API.
Replication Client Side
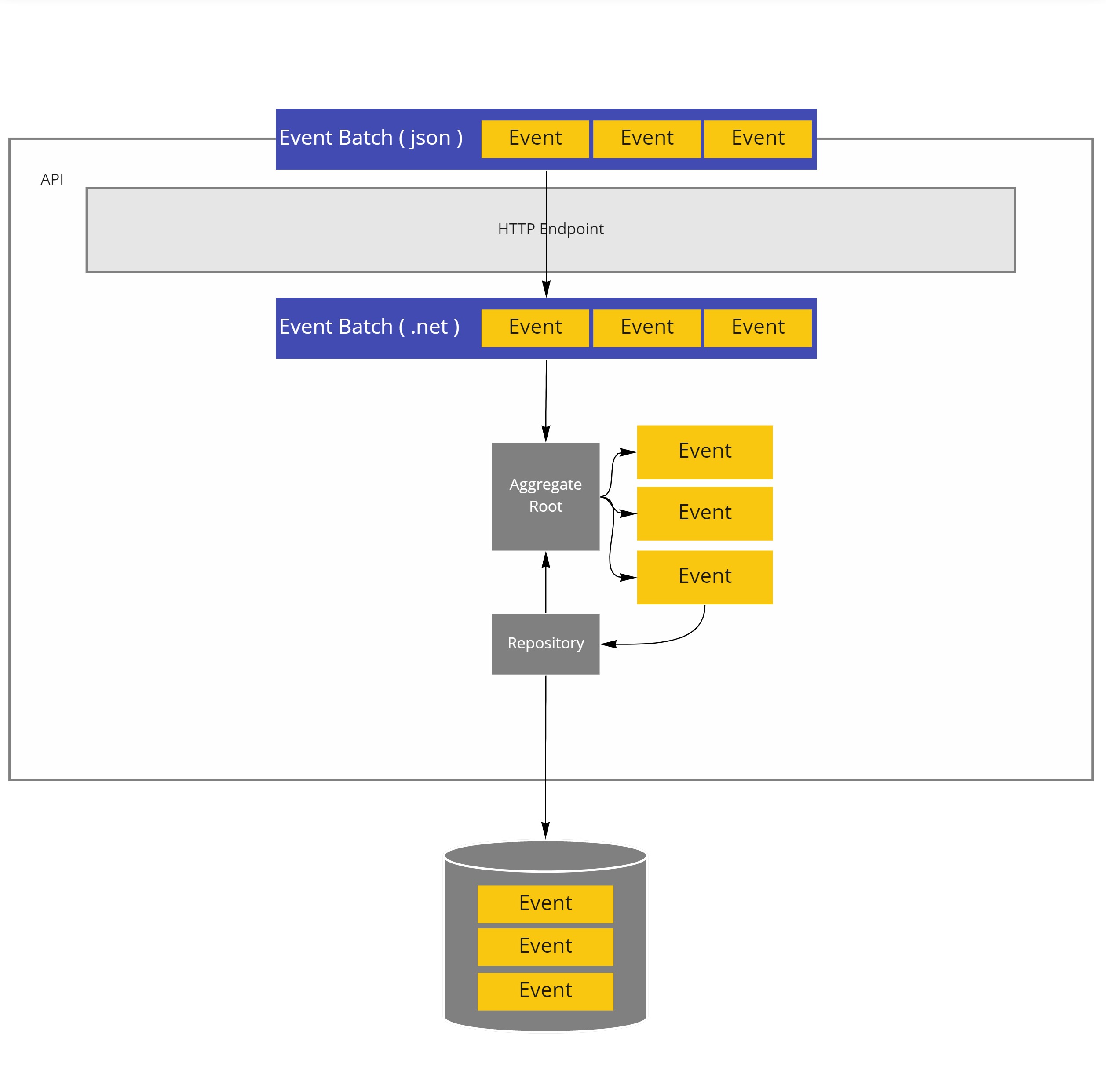
On the client, a replication component scans the eventstore for undispatched events and submits those, in properly partitionined batches, to the API.
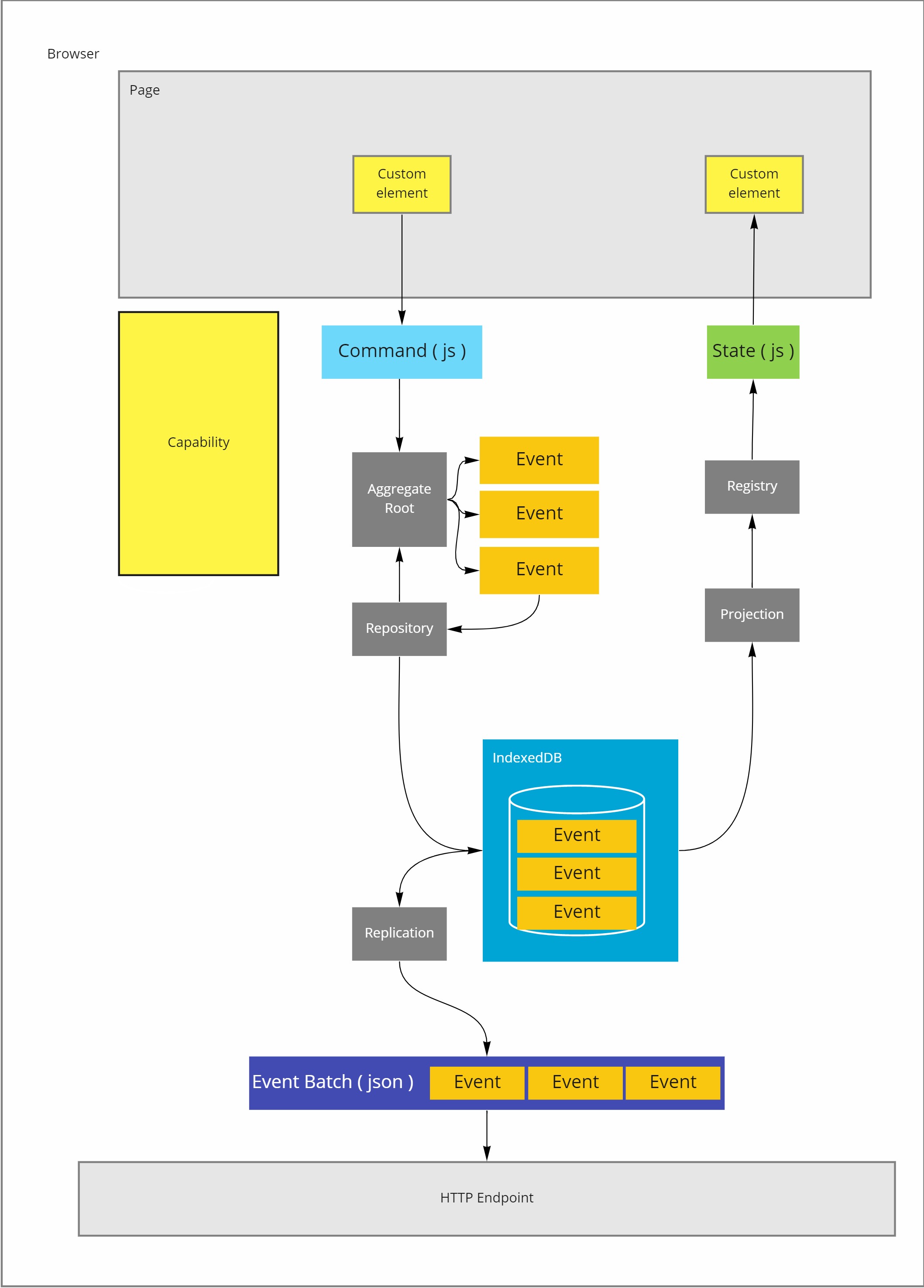
Proper partitioning and batching, most likely per aggregate root, is important for server side conflict detection.
If a batch misses events from a stream or it contains events from other streams, it will be hard for the API to make sense of the replica set.
Replication API Side
First of all the API should allow to download past events.
Next to that it should also accept replica sets, validate them and hand them over to the server side version of the aggregate root for conflict detection and resolution.
When there are no conflicts, which means that the parent of the first event in the replica set is the last event in the aggregate stream, then the aggregate root can append the events to its stream and get them stored in the server side event store.
I will go in depth on conflict resolution strategies in a future post, but it's important to note that this becomes much simpler when working with immutable events than it is when working with mutable state.
The only thing you can do with events is reject, reorder, or leave them.
In that sense event stream conflict resolution strategies are very similar to what you can do with git:
- Reject: Forces the client to resolve the conflict.
- Rebase (upstream): Resolves the conflict by reordering the events, either server changes first or client changes
- Merge: The conflicting branches continue to exist next to each other, but a merge is appended to join them back into a single stream. Conflict resolution events can then be appended to resolve any problem imposed by the branches.
Downsides to this pattern
As with every architectural choice, the upsides are offset by some downsides. This one is no different:
- You need to be in control of both the client and the API to allow event replication to take place. I've never seen a public API allow this type of exchange. (For good reason, see point 4)
- Code duplication between the client and the API leads to additional maintenance work, especially because both are likely programmed in different languages it can be a challenge to keep all business rules equal.
- The above two points require, in my opinion, an organizational structure that allows the same people to work on both the API and the client code. Companies with backend and frontend team differentiation should not attempt to use it.
- Only capabilities where the user can be trusted with all the data allow for this design. In a CQRS or CRUD design, the API can filter data out as part of the query experience. In this design however, all the events must be downloaded to the client in order to support local projection and local aggregate roots. Leaving events out will result in unresolvable conflicts. This implies that a savvy user can see all the information in its raw form.
Back to guide
This article is part of the building offline progressive web apps guide. Return to this guide to explore more aspects of building offline progressive web apps.


