I've been a software architect for more than 20 years now.
During this period I have slowly adopted a step by step process that allows to consistently deliver high quality software to the market.
It works equally well for the teams I'm coaching at customers, as well as when I work alone on side projects.
Should you be looking to improve your delivery process, then I hope this guide can provide you some inspiration.
Note that this process only covers the steps needed to actually deliver software. It doesn't help you to discover which capabilities should be built, nor does it help you to drive people towards the delivered features either. Additional processes are needed to cover those aspects.
Overview of the delivery process
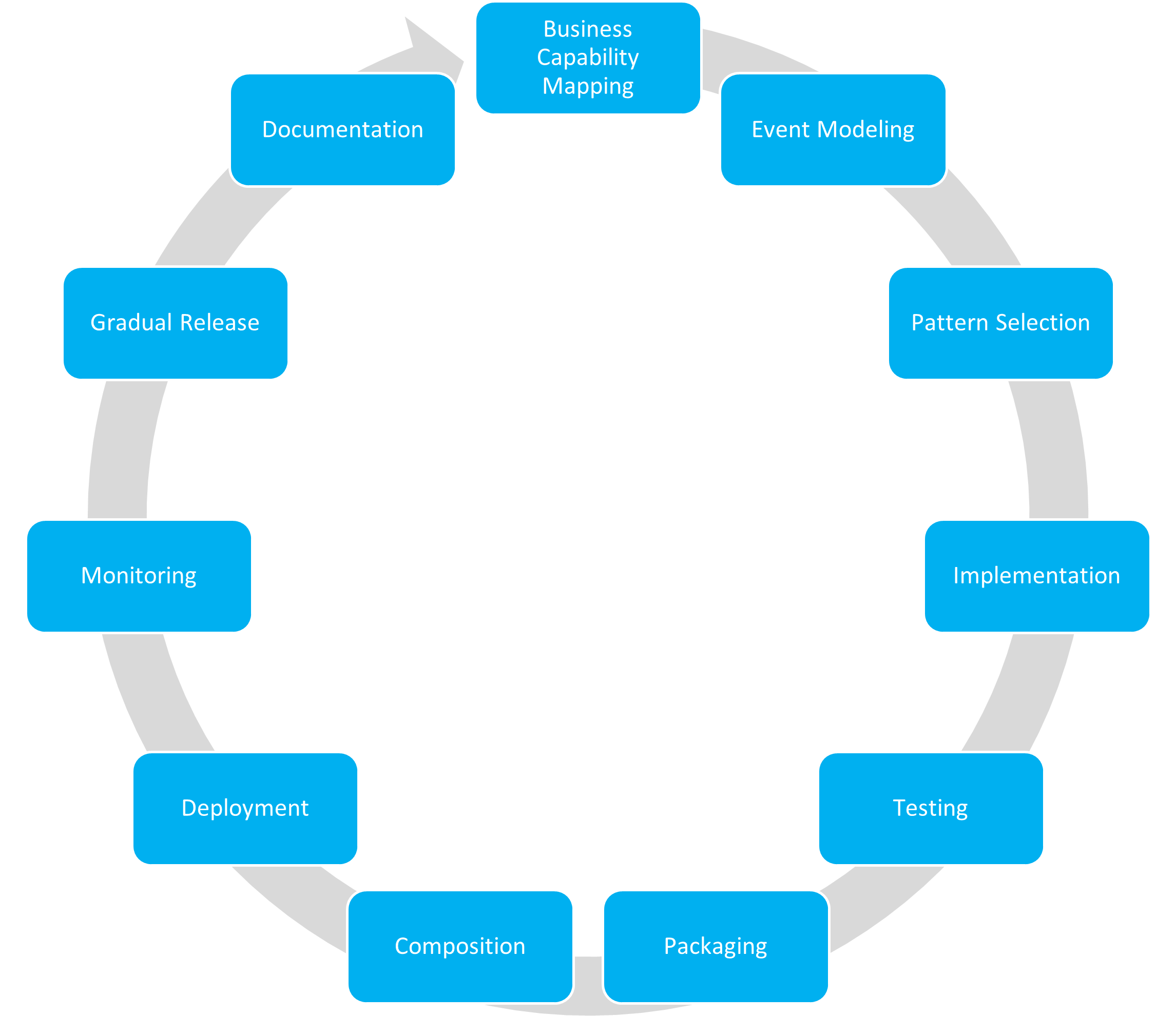
The delivery process consists of 11 steps and is executed iteratively in the following order:
- Business Capability Mapping
- Event Modeling
- Pattern Selection
- Implementation
- Testing
- Packaging
- Composition
- Deployment
- Monitoring
- Gradual release
- Documentation
Eventhough there are quite some steps involved, going through a single iteration usually doesn't take very long, because:
- You can go through the iteration feature by feature, keeping each step small.
- Half of the steps (from testing to gradual release) can, and should, be mostly automated.
Business Capability Mapping
The first step of the process is to understand, and extend, the business capability map.
A business capability map describes what the business, which our software is supporting, is capable of doing at various levels of detail.
This map can be respresented either as a treeview or as a nested view (or combination as I prefer).
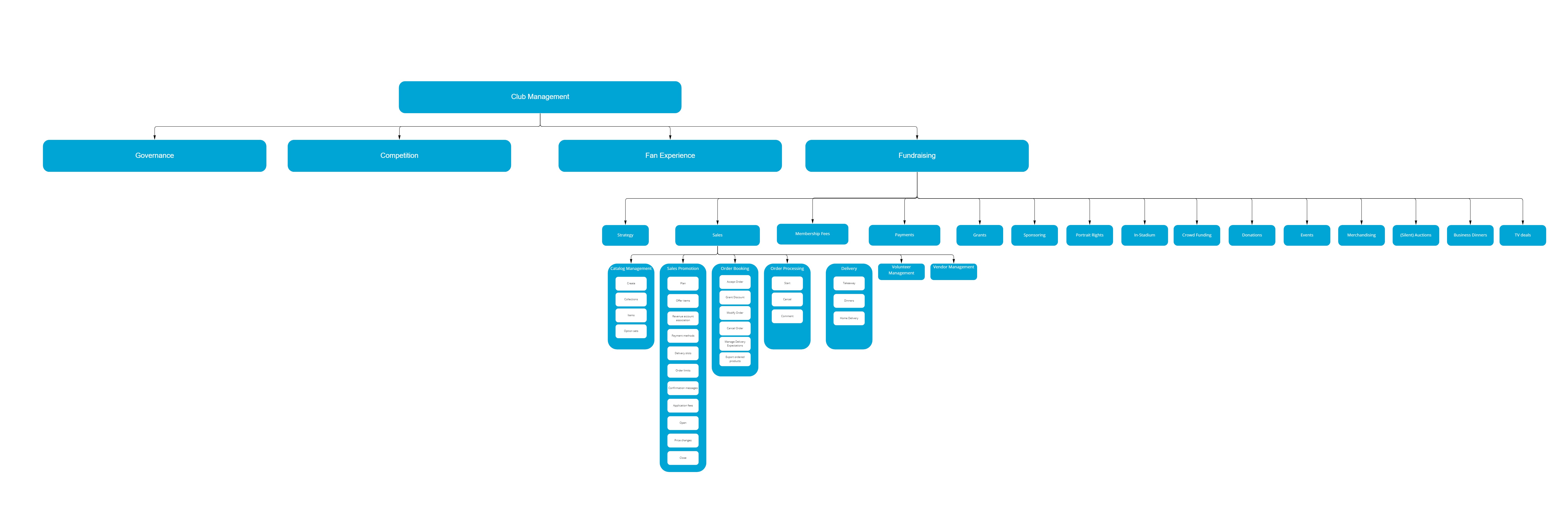
At the top of the map, you can find the main purpose of the business, the capability that explains why it exists. (Level 0)
Lower levels describe, subsequently in more details, which capabilities the business has in order to support the main one.
Creating the bulk of this map isn't part of the delivery process, that is actually done during the discovery process. Check out my post on business capability mapping to learn how to create this map.
In this initial step I will only add the lowest leaves of the tree, by adding the feature I'm about to build, typically at level 4.
Furthermore I'll take note of the parents of this feature, and use them as guidance for making structural decissions later on.
For example:
- The level 1 parent will serve as target for the monitoring step (e.g. fundraising dashboard)
- The level 2 parent will decide where the code will be deployed to (e.g. sales web app)
- The level 3 parent will determine the code library where the feature will be added to (e.g. order booking process component)
- And level 4 will be the feature itself (e.g. place purchase order)
Event Modeling
Every feature is used in context of a business process (usually identified at level 3 of the capability map).
Before I start to work on the code, I first take some time to model this business process using Event Modeling.
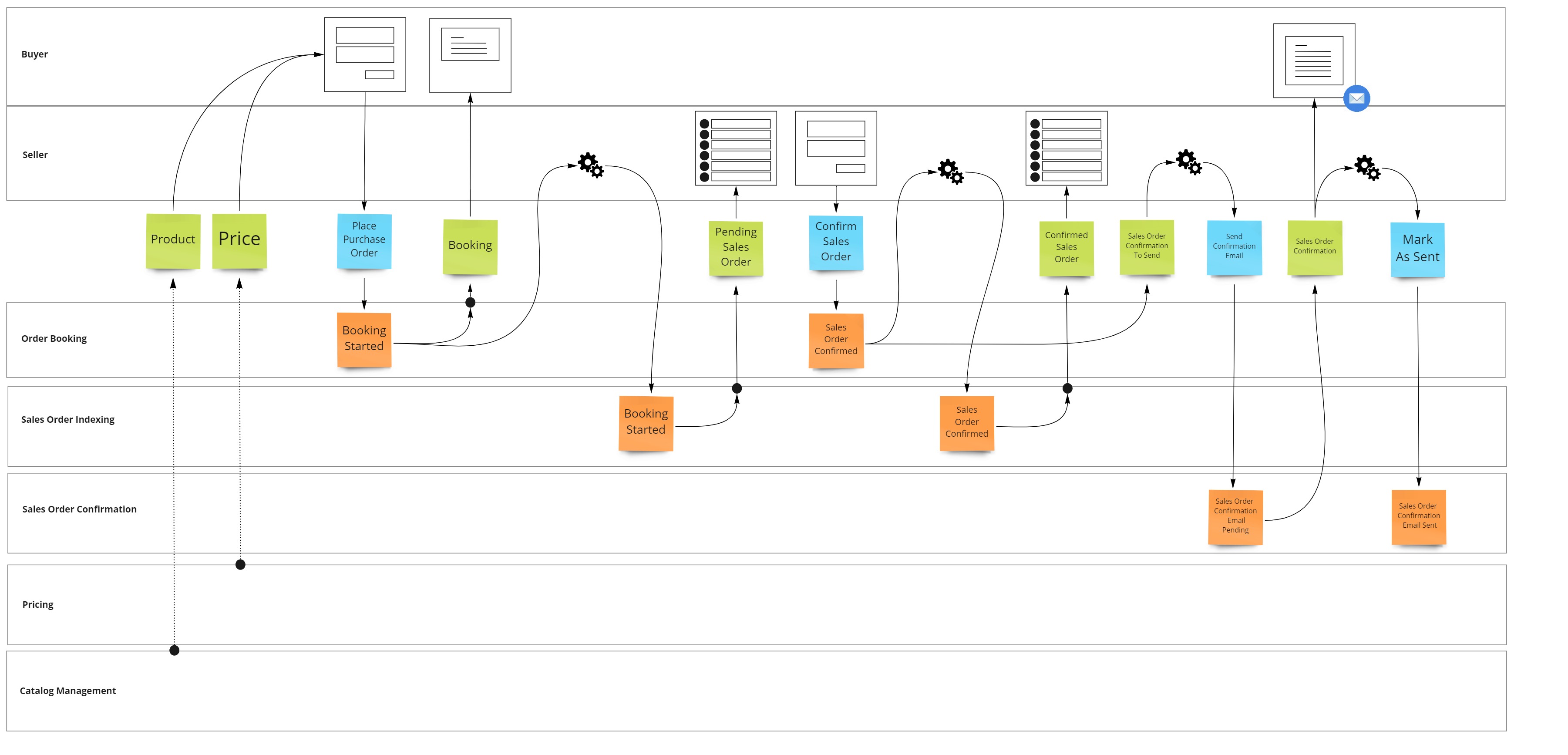
The result of this exercise will teach me:
- Which people will use the new capability
- What input data is required to use it
- How the data will flow throughout the system
- Which downstream side effects are introduced because this new feature (e.g. a new confirmation mail)
Pattern Selection
The event model will then serve as input for pattern selection.
There are thousands of design patterns to choose from, but in reality I believe we only need 9 core patterns.
Why only 9?
Well, to say it with the wise words of software legend Grady Booch:
"At a certain level of abstraction, all complex systems are message passing systems"

And message passing systems only have 3 types of messages: commands, events and state.

This leaves us with only 9 core processing patterns, needed to transition from one message type to any other.
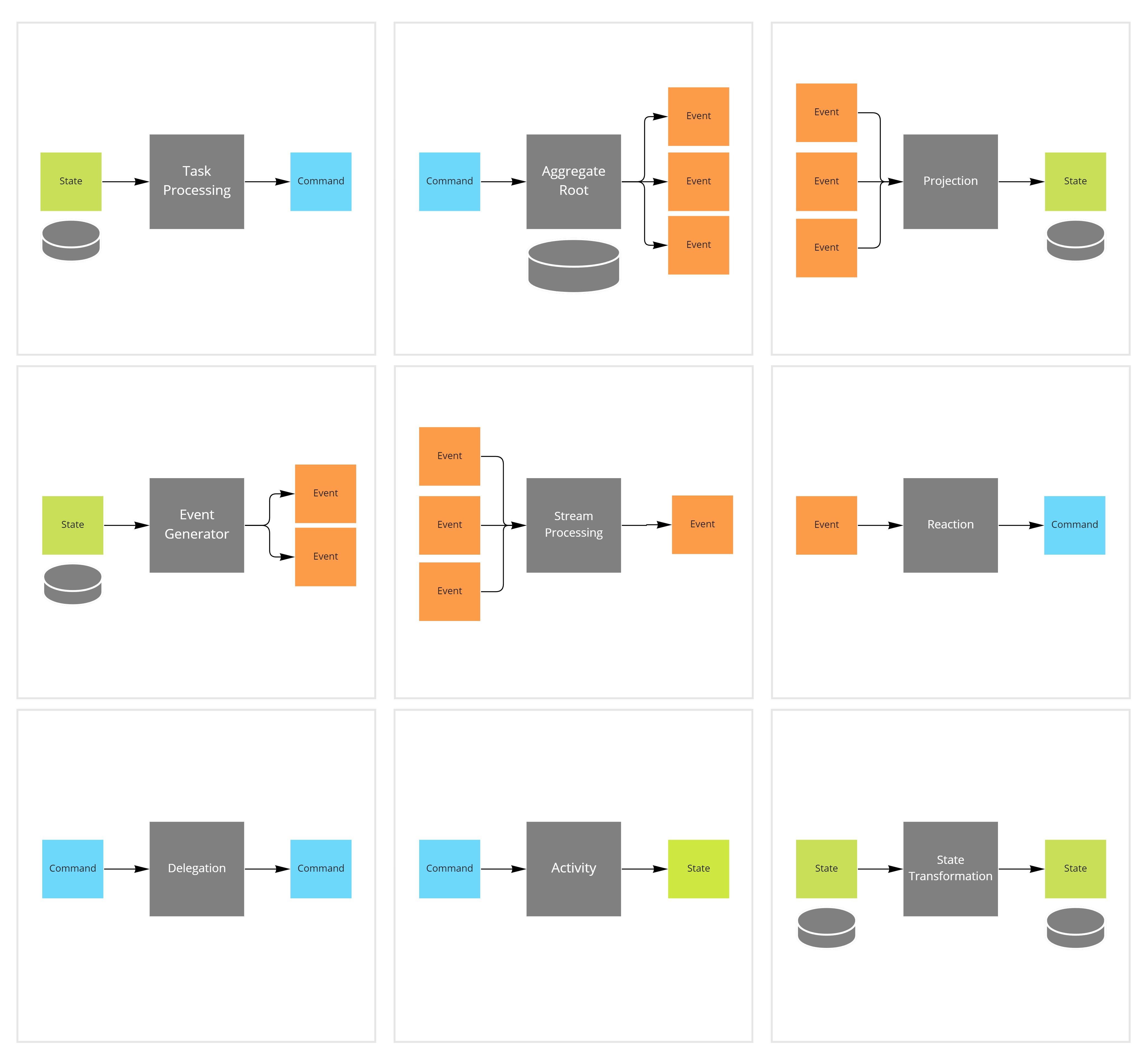
The pattern of choice can easily be derived from the event model, by looking at the message type transitions.
Implementation
For all of these core patterns, it's usefull to accompany them with a few supporting patterns that can serve as adapters to the hosting, storage and integration infrastructure.
Note that this idea of a core, with support, is a common characteristic of almost all design guidance (such as hexagonal design, ports and adapters, onion architecture, clean architecture, ...)
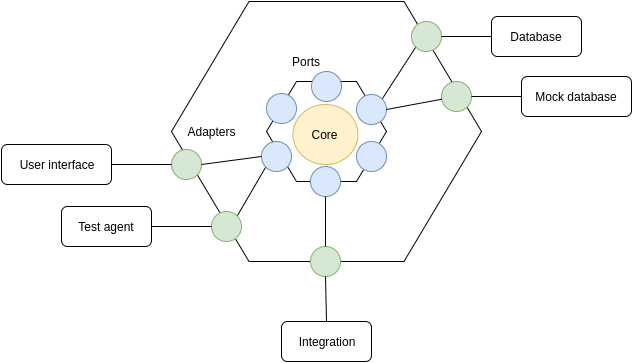
As an example, I tend to pair the Aggregate Root pattern with the Repository pattern.
And each pattern that needs to load state typically gets paired with a Registry pattern to get access to said state.
One of the reasons the implementation of the core pattern needs to be paired with a supporting pattern is test speed.
Test speed gets heavily influenced by the amount of IO that the test set needs to perform during the test run.
As all business logic will reside in the core pattern implementation, you want to ensure that this core pattern performs no IO at all, so that it can be tested in hundreds, if not thousands of test scenarios per second.
This should lead to a top level component entry point that looks something like this (in pseudo code):
Controller
{
Post(id, input)
{
// supporting pattern performs load IO
var core = _repository.Get<AggregateRoot>(id);
// core pattern performs no IO
var result = core.ExecuteCommand(input);
// supporting pattern performs outbound IO
_repository.Save();
}
}
When all IO is performed at the boundary of the entry point, by the supporting pattern, then the core can be kept purely functional and void of any IO.
All load IO should thus be performed at the beginning of the method invocation, and all outbound IO at the end.
Next to pushing the IO to the boundary, it is also important that the implementations of both the core pattern and the supporting patterns are atomic, retriable and idempotent (especially in a cloud environment where operations are more likely to fail):
- Atomic: Implies that the operation should perform only a single write at a time. This to avoid partial completion on failure.
- Retriable: If that write would fail, due to transient exceptions, the operation must be retried until it succeeds.
- Idempotent: In case the operation gets retried, yet it did already succeed before, the outcome of the operation should still be the same.
Controller
{
// Client needs to retry in case of failure
Post(id, input)
{
// naturally idempotent
var core = _repository.Get<AggregateRoot>(id);
// implementation must take idempotency in mind
var result = core.ExecuteCommand(input);
// must be atomic and idempotent
_repository.Save();
}
}
Testing
Keeping test execution speed high is crucial for maintaining a high quality code base, as fast tests provide quick feedback and quick feedback allows you to fix issues faster.
Should the total test run exceed the typical human attention span, 10 seconds, you will also loose concentration and start watching cat videos multitasking, further slowing down your development cycle.
The implementation strategy allows a testing strategy which supports this need.
My current testing strategy looks like this:
- Use a few narrow integration tests to the test the IO embedded in the supporting pattern, and serialize the output of these tests to a verification file.
- Build an in memory suite of test stubs, and use contract tests to validate these stubs against these verification files.
- Use unit testing, to test the core pattern in as many scenarios as possible, using these stubs as input.
- Use component tests to test the interaction of the top level component entry point, where the supporting patterns are mocked out to prevent any IO from occuring.
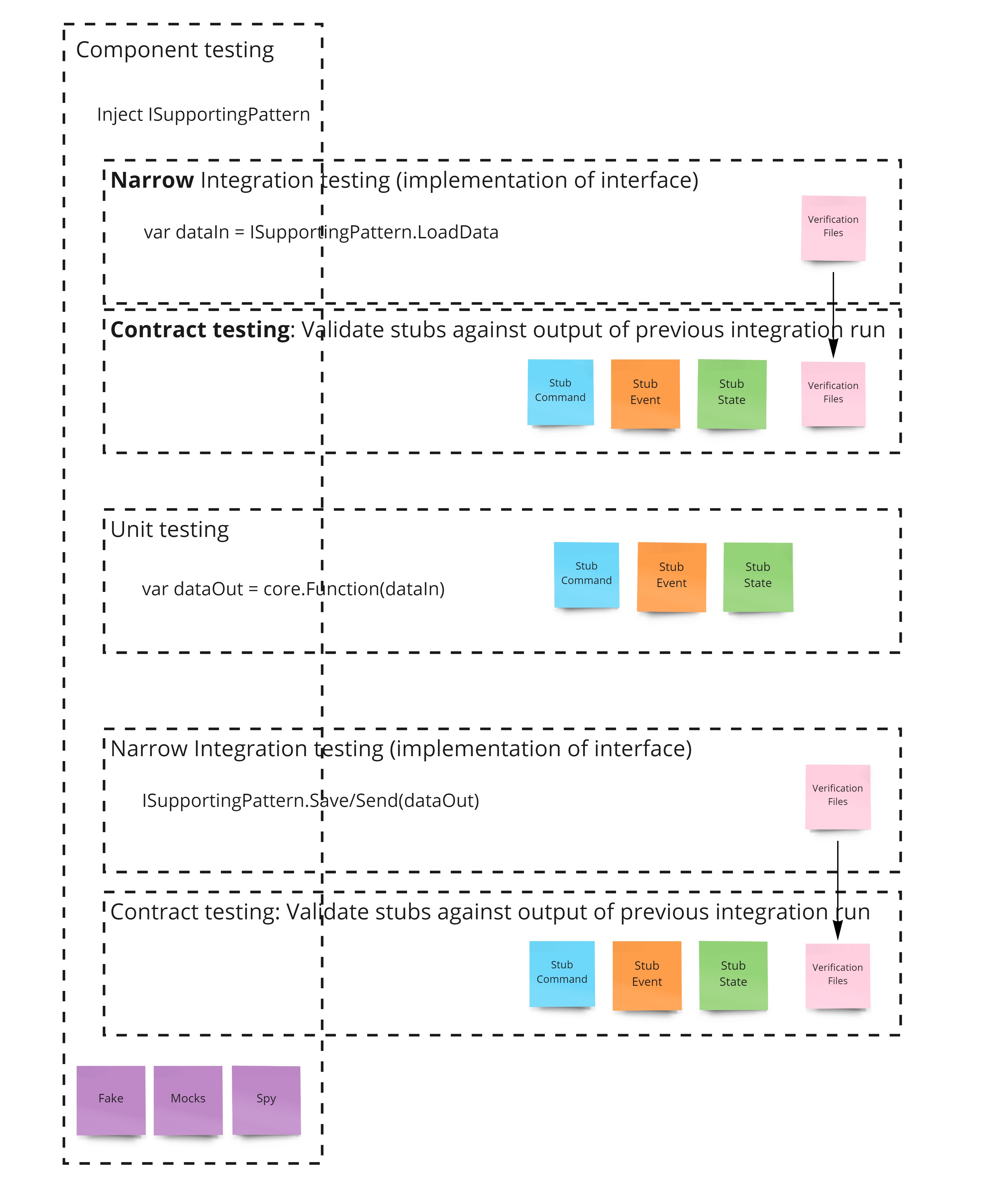
By applying this strategy, you can limit the impact of IO to a few narrow integration tests for the supporting pattern and execute all the other tests in memory.
This should allow you to run hundreds, or even thousands of test scenarios per second and keep your full run for this capability below the 10 second mark.
When you have a fast test suite in place, you can run the suite continuously while working on the code base, so that it can provide feedback instantly.
And of course you also want to run the test suite as part of your packaging, composition and deployment pipelines.
Sometimes it's worth to point out what is not included in the strategy: End to end testing across different capabilities is explicitly not included in the strategy. This practice has been replaced by the gradual release practice at the end of the process.
Packaging
Getting the code for the new capability deployed to its runtime environment happens in three distinct steps: packaging, composition and deployment.
In this first step the implementation of the core pattern, the supporting pattern and the component entry point get packaged up, using a build pipeline.
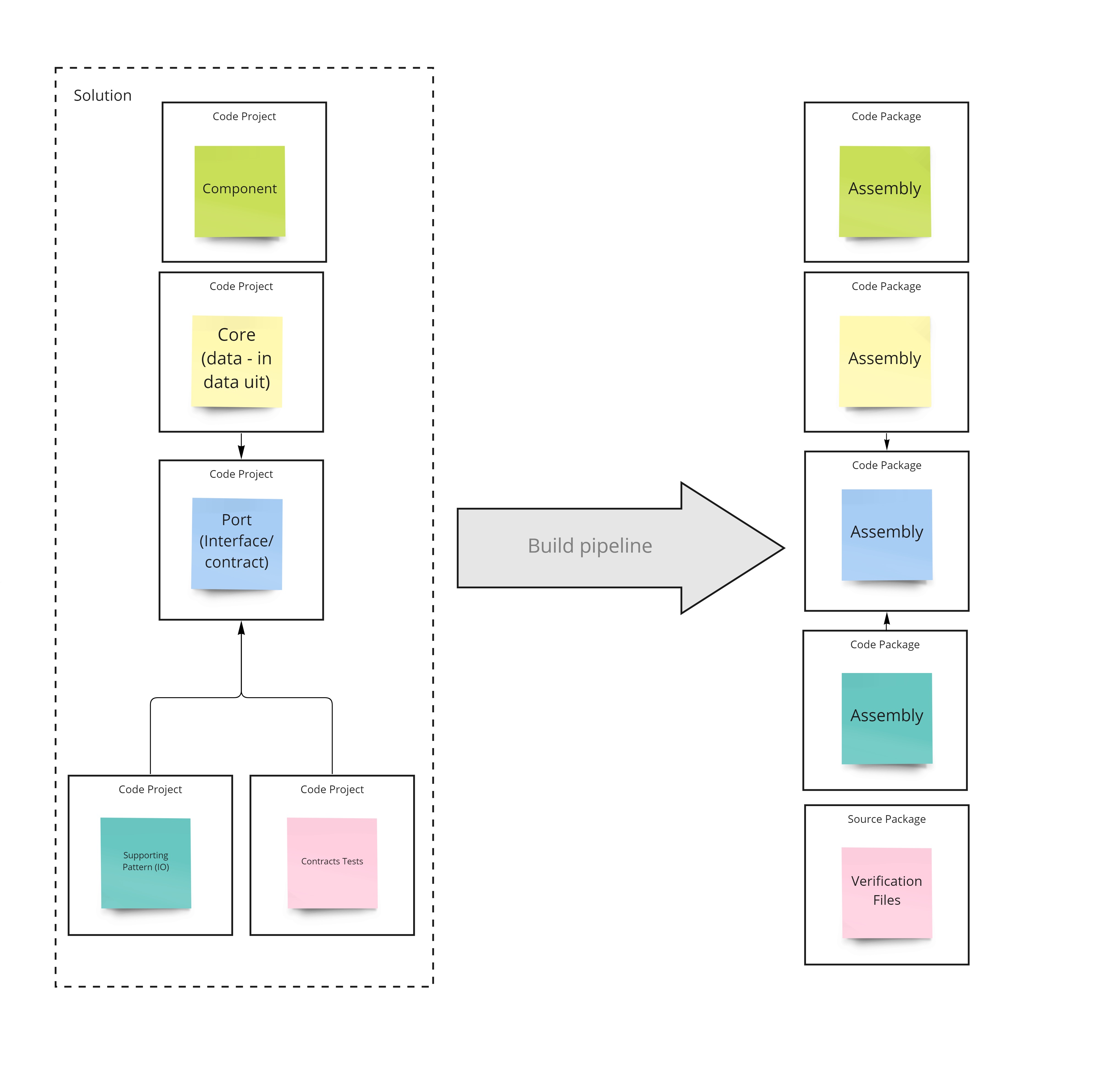
In my blogpost on UI composition with yarn you can learn how to set up a packaging pipeline for frontend components using Github Actions, Yarn and Github Packages.
On the server side, the same set up can be achieved using Nuget package manager.
The goal of packaging up capabilities individually first, is to decouple their implementation from the actual decission where they will be hosted.
Composition
Integrating features, offered by the capability level packages, into a hosting runtime is performed in the composition step.
For each hosting app, there is a separate solution which references the capability packages and is home to the host startup and configuration code.
This solution has its own build pipeline that converts the hosting code into a hosting specific container package.
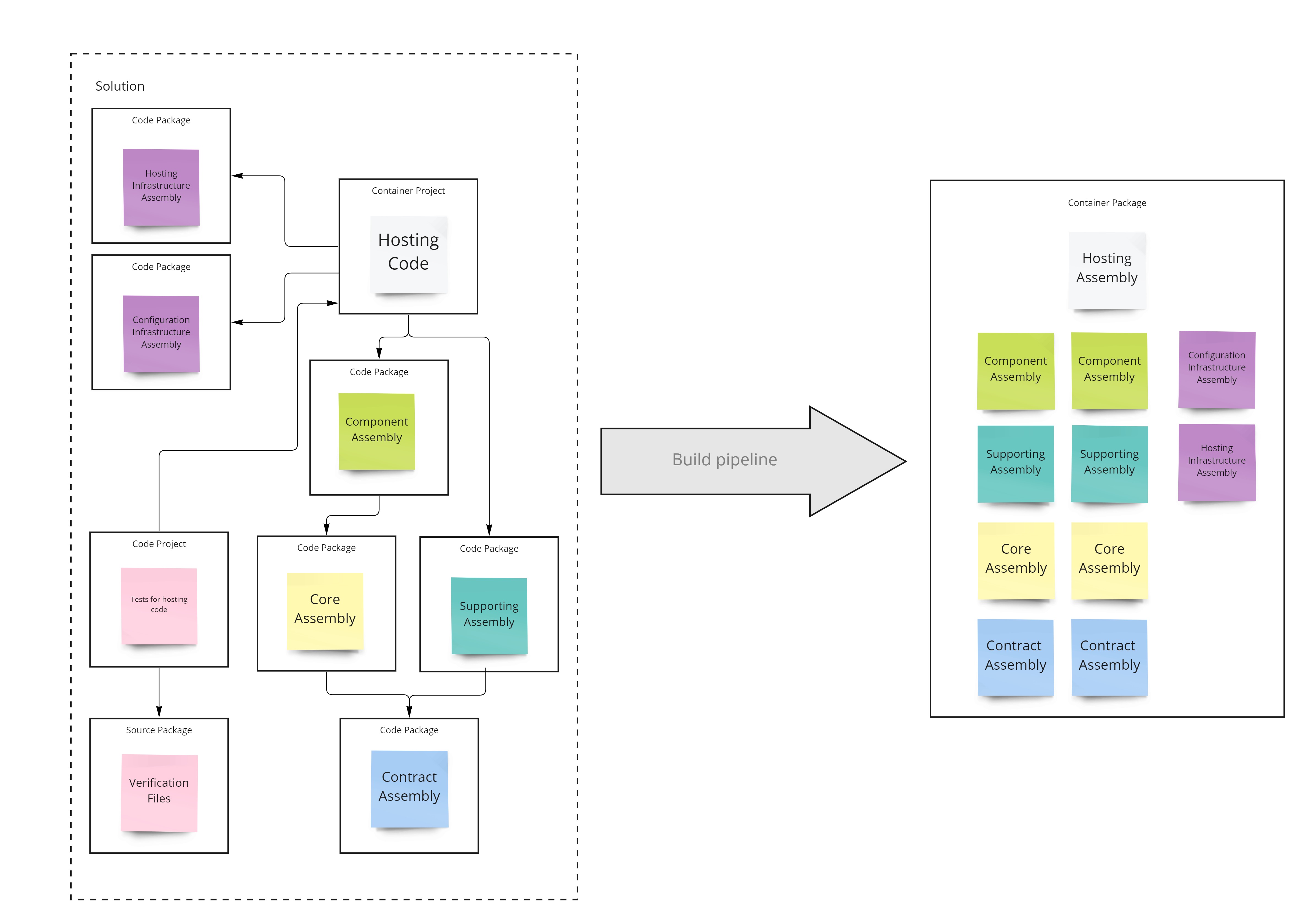
The word container should be interpreted looselyhere, as it is defined in the C4 model.
Yes it could be a docker container, but it could also be a webpack bundle, a service fabric application manifest, or even just a folder with some files in it. It depends on the nature of the hosting technology in question.
In the blog post on UI composition with yarn you can find a description of how I compose the package definition for a Progressive Web App (PWA) from the npm packages exposed by the hosted capabilities.
Composing the actual PWA package is currently embedded in the dish run tool
Deployment
After the container package has been built, by its build pipeline, the deployment can be kicked off.
Deployment typically has two pipelines which need to run.
- The infrastructure provisioning pipeline
- The container package deployment pipeline
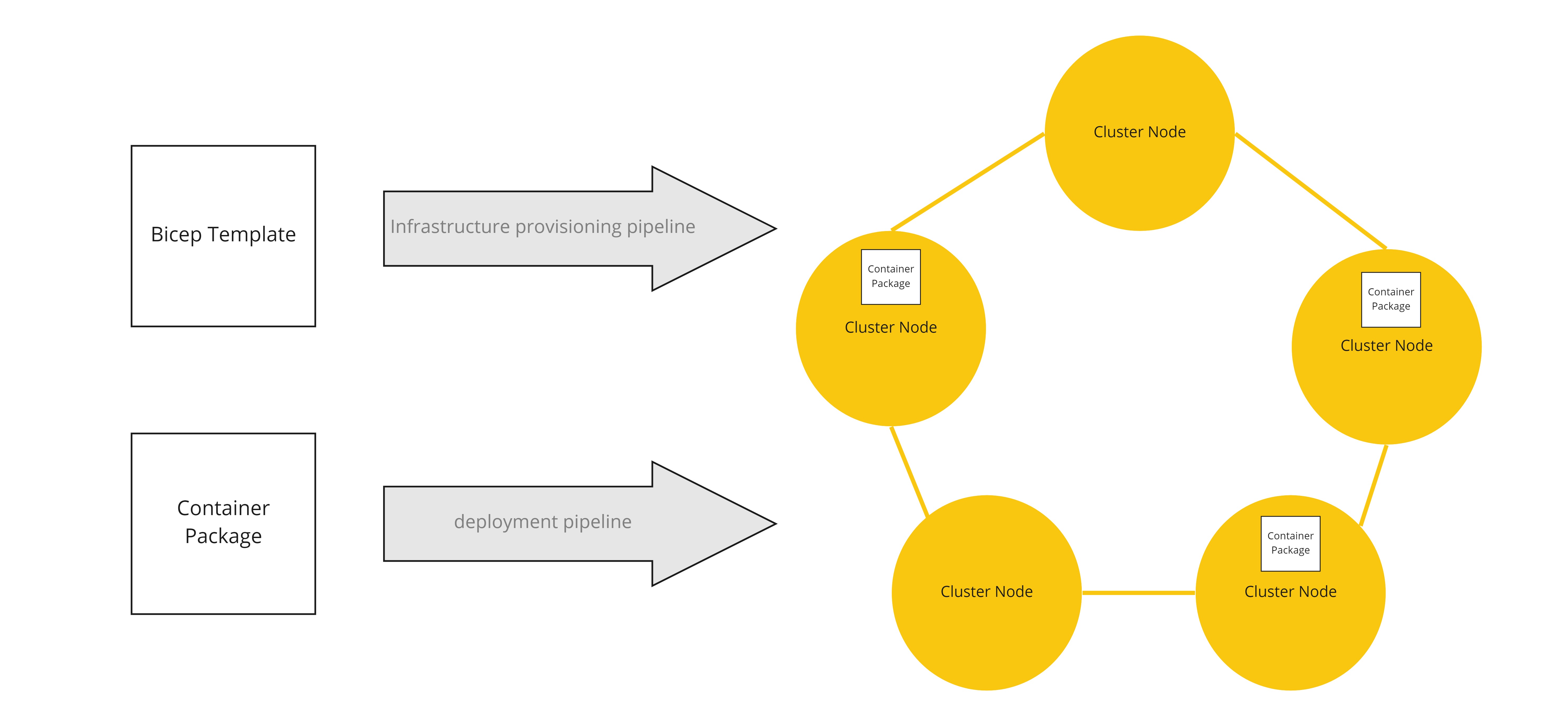
The infrastructure provisioning pipeline will set up the hosting environment itself. In Azure this task is typically achieved by running an ARM template, or a Bicep script.
Once the infrastructure is provisioned, the container package can be deployed to it through its own deployment pipeline:
- For my PWA's this task is performed by the dish publish tool
- For my web api's I use the webapps-deploy action available in Github Actions.
It's important to note that features will first be deployed without actually being released to the users (using a feature flag in off mode).
Monitoring
Before I gradually release the new capability to the users, I'll first make sure the monitoring and alerting gets improved with insights into the parts of those system that could be impacted by the release of the feature.
Usually this means reviewing, and potentially modifying, the graphs on the dashboards that I have set up in Application Insights for the respective level 1 capability where this feature belongs under.
Gradual release
After ensuring the monitoring is set up, I'm ready to start releasing the feature gradually to the public.
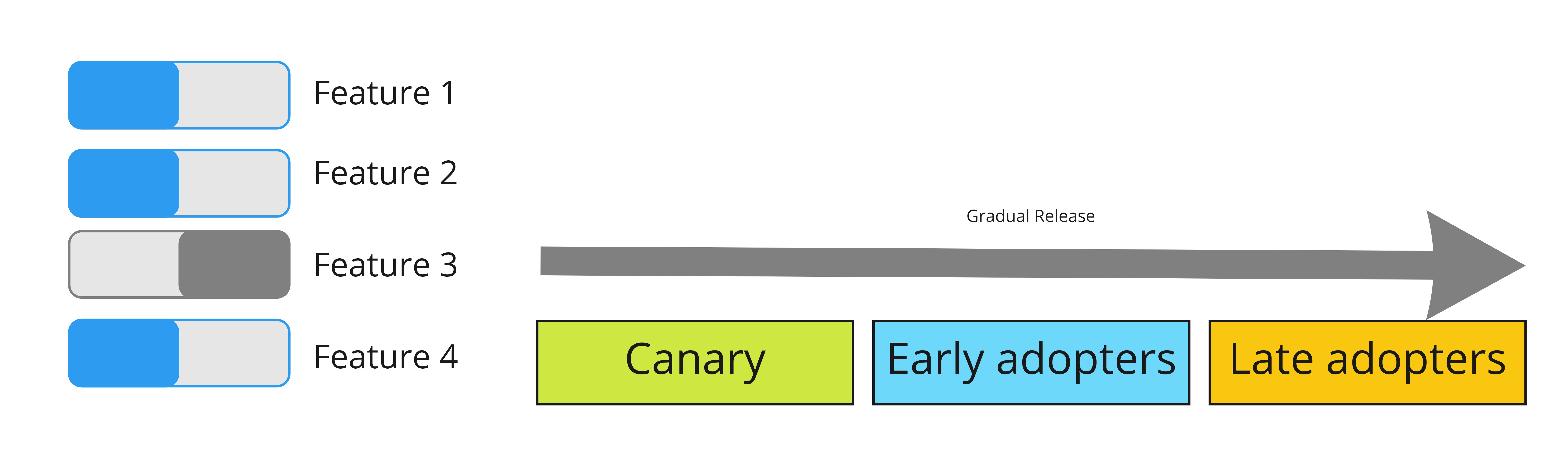
By using contextual feature flags I can enable the feature for different sets of users at a time, while keeping an eye on the monitoring dashboards.
The goal of this practice is to limit the impact of any bugs that could make it to production, instead of spending a lot of manual effort to prevent any bugs from getting there (they get there no matter how hard you try).
Releasing a feature is a fairly slow process. While it is being adopted by more and more people, there will be some slack time.
Documentation
During this slack time, I will perform a review of the (mostly still internal) documentation.
To structure my documentation, I'm relying on the Diátaxis framework.

It aims to structure the documentation to the needs of users in each cycle of their interaction with a product.
It identifies four modes of documentation - getting started tutorials, how-to guides, technical reference and explanations.
Each of these modes answers to a different user need (practical or theorethical knowledge), fulfils a different purpose (during study or work). Each of these modes requires a different approach to how the document is structured.
Repeat
And of course, the business capability map is part of this internal documentation, bringing the process full circle.
Now I'm ready to build and release yet another feature.


